 夜莺功能介绍
夜莺功能介绍
Grafana 更擅长监控面板的管理,N9e 更擅长告警规则的管理。

# 1. 告警规则
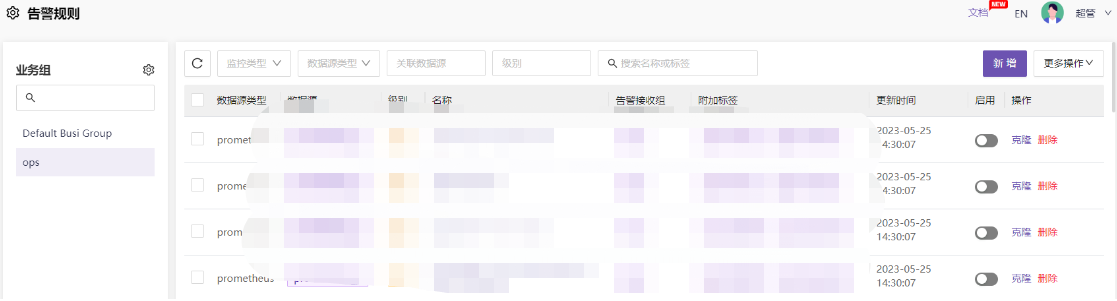
可以根据实际情况创建多个业务组(infra),然后就可以把涉及到多个业务组(infra)的告警规则进行分开管理。
默认导入进来的规则原则上是没有生效的,需要做一些额外配置。点开告警规则名称,进入配置页面。

基础配置
- 规则名称: 自定义规则的名字
- 附加标签:这个标签是key=value的格式,如果打了一个标签,比如servce=dream,那么可以在后续的规则处理中过滤
- 备注:告警规则的附加备注
规则配置
分为Metric和Host机器类型的告警
Metirc类型的告警
- 关联数据源: 配置的数据源时序库数据库
- 告警条件:当服务主机到达这个条件就会发生告警警报
- PromQL:用于Prometheus监控系统的查询语言,用于从Prometheus存储中检索和聚合指标数据。PromQL是一种非常灵活和可扩展的查询语言,可以支持各种不同类型的指标数据分析和检索。这里我们写一个触发条件,比如mem_available_percent < 50他就会触发报警
- 触发告警:这里有三个等级,最严重优先级最高的就是一级报警,依次往后。当然也可以添加其他的告警条件,这里是可以添加多个告警条件来触发告警
- 级别抑制:打开后,高级别的告警就会直接抑制低级别的告警,不会重复报警
- 执行频率:每 xx 秒执行一次,连续持续 xx 秒依然满足告警规则,则会触发告警
Host类型的告警
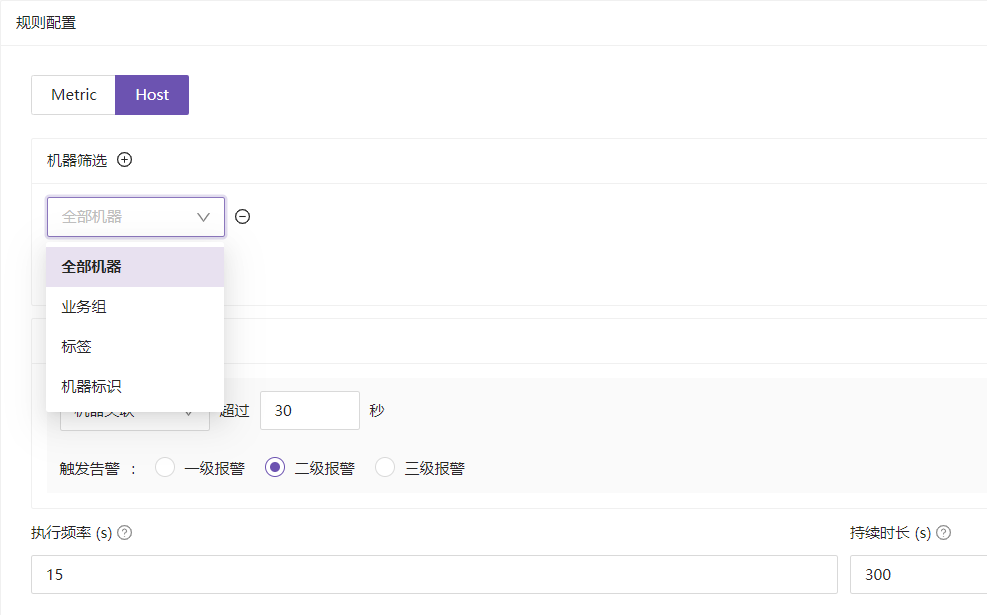
机器的筛选:
- 业务组: 就是一个项目组一个组里面的机器,或者说一个项目组集群筛选
- 标签:在基础设施里面给我们监控的机器打上特定的标签来筛选
- 机器标识:就是具体的某一台主机筛选或多台主机筛选
机器告警规则:
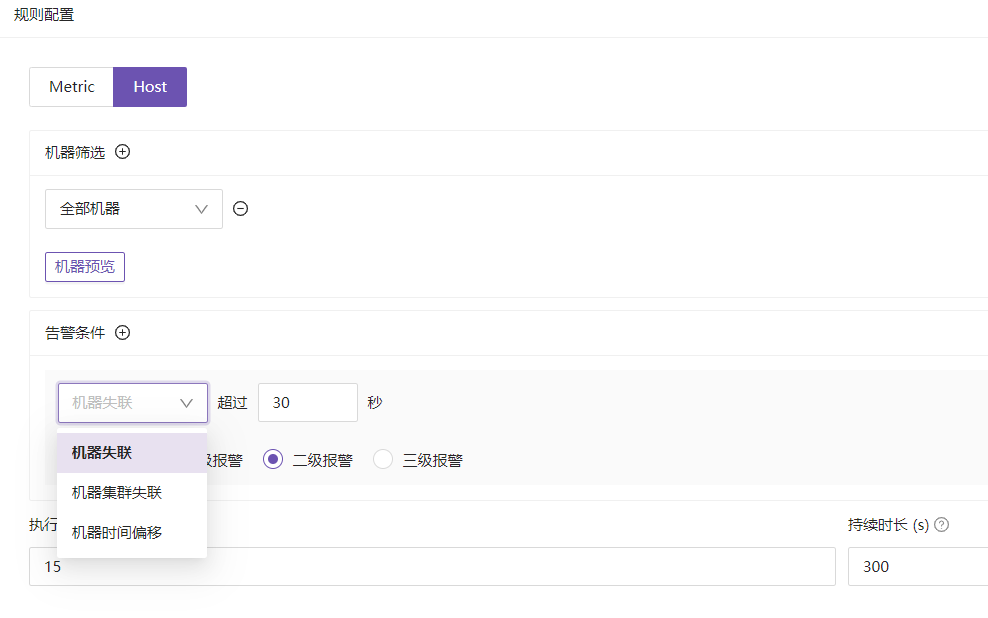
- 机器失联: 就是机器失去连接,连接状态出问题,或者机器死机情况
- 机器时间偏移: 机器时间时钟的监控,监控对时间有要求,如果时间偏移大了,会影响数据的同步查看
- 机器集群失联:设置集群失联比例,比如一个机器集群如果有百分之60的机器都失联了,那么就会发出告警。
机器类型告警也可以进行多个告警条件的设置:级别抑制、执行频率、持续时长
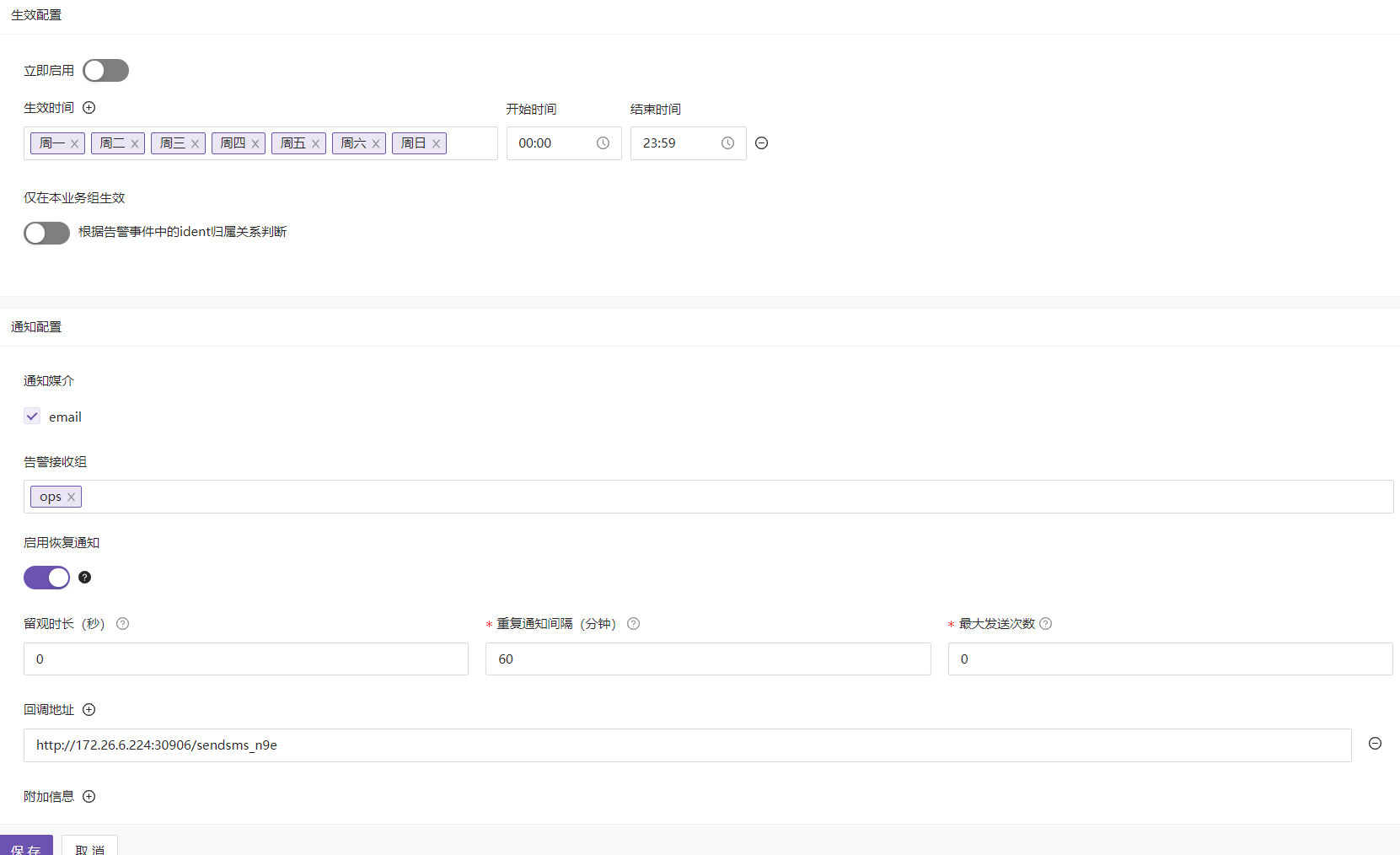
生效配置 用来配置该告警规则在什么时间段,什么业务组生效。
通知配置 通知配置则是配置通知媒介,也就是如果产生了告警,应该通过哪些渠道发到哪些地方。
- 通知媒介:通知告警的方式,比如emall、短信等等
- 告警接受组:哪个业务组接受这些告警
- 启动恢复通知:告警恢复了,是否通知
- 留观时长:如果告警出现的问题在留观时长没有到之前,偶尔的恢复正常,还是不算已经恢复告警,只有超过留观时长,运行的错误没有出现后,才会恢复正常,不然还是会告警。 比如留观时长设置5分钟,如果cpu占有率突然到达了百分之80以上并且符合告警条件,如果在处理告警错误的时间中,5分钟之内这个cpu占有率偶尔下降到了正常值,但是一会儿又升高了,那么这个告警就不会恢复,如果这个cpu占有率5分钟之后还是正常值,那么这个告警就恢复。
- 重复通知间隔:通知的间隔,告警通知一次后,60分钟后再发送告警通知
- 最大发送次数:发送通知的最大次数,不会一直发。
- 回调地址:如果发生故障告警,会把故障回调给故障处理平台进行处理。收到告警内容,然后做相应的处理、清理磁盘等。目前是通过回调地址调用短信/微信 webhook来发送告警。
- 附加信息:分为预案链接,仪表盘链接,描述。 预案连接就是如果发生此类的告警,事先做了一个预案来解决这个故障,那么就可以把那个预案的链接贴上。 仪表盘链接:故障的机器的仪表盘链接。 描述:备注这个告警规则。
# 2. 内置规则

提供一套普适性的规则,旨在降低使用门槛。内置的告警规则默认不会生效,如果使用某个规则,可以把它克隆到告警规则中。
# 3. 屏蔽规则

屏蔽规则也是按业务组分的,可以设置告警屏蔽的时间,屏蔽的标签,屏蔽的数据内容时间等。创建屏蔽规则的方式:
- 手动创建屏蔽规则
- 基于活跃告警或历史告警,一键屏蔽
# 4. 订阅规则


如果一个告警在一段时间内还没进行处理,怎么办?
要么不是重要的告警 —— 把规则删了吧,留之无用。
要么是解决不了的告警 —— 升级吧,让更多人知道。
在夜莺中,在订阅规则中可以实现告警升级,可以重新定义告警级别、通知方式。
第一种应用场景:运维升级告警到研发。比如在一个公司,小王在运维部门,小李在开发部门。小王专门负责收集这些业务告警处理。有一天小李开发上线了一个自己业务叫Dream-stack,想要亲自查看获取这个业务的告警,但是这个告警规则什么的权限都是小王掌握的,并且配置告警规则的时候,告警接受组也是小王的运维团队,但是因为小王跟小李平时关系很好,这个时候小王就开启了夜莺的订阅规则,把只要是关于Dream-stack标签的告警规则的告警都转发告警接受组为小李,这个时候小李也能实时收到这个业务的告警信息了。
第二种应用场景:研发升级告警到运维。在一家公司,小李在开发部门,小王在运维部门。有一天,上线的一个服务业务突然告警故障,并且那个告警规则接受组是小李团队,这时候小李收到告警后,就开始处理故障,结果越搞越砸,故障越来越多,而且一直没有解决,小李就焦虑,想着如果这个故障处理不了就发给小王处理,然后小李就把这个订阅告警的订阅持续时长字段改为了10分钟,如果10分钟这个告警还没有解决,就把这个告警通过一级别的告警级别推送给小王。
第三种应用场景:L1升级到L2
# 5. 活跃告警、历史告警
查看当前有哪些告警信息,以及历史的告警记录。
# 6. 记录规则
记录规则(Record Rule)实现基于现有指标数据计算出新指标数据,通过定时周期(interval)执行计算规则,形成新的指标时序数列,生产中记录规则往往用于简化PromQL复杂性。
夜莺系统中配置记录规则,并不是比如生成Rule规则文件下发到Prometheus中,而是采用【远程查询】- 【解析】 - 【远程写入】方式,涉及到远程读写,所以这里可能需要关注网络IO情况。 因为Prometheus配置管理这块较弱,没有提供配置管理功能,也没有相关接口,只能进行文件加载,若要搞成下发配置则需要agent才行,对于后面的告警规则一样,也是远程读取数据自行管理触发告警事件,而没有使用Rule Alarm方式。