 夜莺(nightingale)介绍
夜莺(nightingale)介绍
# 前言
夜莺官网地址:https://flashcat.cloud/docs/content/flashcat-monitor/nightingale/introduction/
github地址:https://github.com/ccfos/nightingale
# 概述
All-in-one 的开源观测平台 开箱即用,集数据采集、可视化、监控告警于一体 推荐组合方案 Prometheus + AlertManager + Grafana + ELK + Jaeger
# 功能和特点
- 开箱即用
- 支持 Docker、Helm Chart、云服务等多种部署方式,集数据采集、监控告警、可视化为一体,内置多种监控仪表盘、快捷视图、告警规则模板,导入即可快速使用,大幅降低云原生监控系统的建设成本、学习成本、使用成本;
- 专业告警
- 可视化的告警配置和管理,支持丰富的告警规则,提供屏蔽规则、订阅规则的配置能力,支持告警多种送达渠道,支持告警自愈、告警事件管理等;
- 云原生
- 以交钥匙的方式快速构建企业级的云原生监控体系,支持 Categraf (opens new window)、Telegraf、Grafana-agent 等多种采集器,支持 Prometheus、VictoriaMetrics、M3DB、ElasticSearch、Jaeger 等多种数据源,兼容支持导入 Grafana 仪表盘,与云原生生态无缝集成;
- 高性能 高可用
- 得益于夜莺的多数据源管理引擎,和夜莺引擎侧优秀的架构设计,借助于高性能时序库,可以满足数亿时间线的采集、存储、告警分析场景,节省大量成本;
- 夜莺监控组件均可水平扩展,无单点,已在上千家企业部署落地,经受了严苛的生产实践检验。众多互联网头部公司,夜莺集群机器达百台,处理数亿级时间线,重度使用夜莺监控;
- 灵活扩展 中心化管理
- 夜莺监控,可部署在 1 核 1G 的云主机,可在上百台机器集群化部署,可运行在 K8s 中;也可将时序库、告警引擎等组件下沉到各机房、各 Region,兼顾边缘部署和中心化统一管理,解决数据割裂,缺乏统一视图的难题;
- 开放社区
- 托管于中国计算机学会开源发展委员会 (opens new window),有快猫星云 (opens new window)和众多公司的持续投入,和数千名社区用户的积极参与,以及夜莺监控项目清晰明确的定位,都保证了夜莺开源社区健康、长久的发展。活跃、专业的社区用户也在持续迭代和沉淀更多的最佳实践于产品中;
# 使用场景
- 如果希望在一个平台中,统一管理和查看 Metrics、Logging、Tracing 数据。参考阅读:不止于监控,夜莺 V6 全新升级为开源观测平台 (opens new window)
- 如果在使用 Prometheus 过程中,有以下的一个或者多个需求场景:
- Prometheus、Alertmanager、Grafana 等多个系统较为割裂,缺乏统一视图,无法开箱即用;
- 通过修改配置文件来管理 Prometheus、Alertmanager 的方式,学习曲线大,协同有难度;
- 数据量过大而无法扩展您的 Prometheus 集群;
- 生产环境运行多套 Prometheus 集群,面临管理和使用成本高的问题;
- 如果在使用 Zabbix,有以下的场景:
- 监控的数据量太大,希望有更好的扩展解决方案;
- 学习曲线高,多人多团队模式下,希望有更好的协同使用效率;
- 微服务和云原生架构下,监控数据的生命周期多变、监控数据维度基数高,Zabbix 数据模型不易适配;
- 了解更多Zabbix和夜莺监控的对比,推荐您进一步阅读Zabbix 和夜莺监控选型对比 (opens new window)
- 如果您在使用 Open-Falcon (opens new window):
- 关于 Open-Falcon 和夜莺的详细介绍,请参考阅读:云原生监控的十个特点和趋势 (opens new window)
- 监控系统和可观测平台的区别,请参考阅读:从监控系统到可观测平台,Gap有多大 (opens new window)
- 我们推荐您使用 Categraf (opens new window) 作为首选的监控数据采集器:
- Categraf (opens new window) 是夜莺监控的默认采集器,采用开放插件机制和 All-in-one 的设计理念,同时支持 metric、log、trace、event 的采集。Categraf 不仅可以采集 CPU、内存、网络等系统层面的指标,也集成了众多开源组件的采集能力,支持K8s生态。Categraf 内置了对应的仪表盘和告警规则,开箱即用。
# 1. 夜莺架构
夜莺 6.x 版本相比 5.x 在架构上做了巨大的调整,之前服务端有两个模块,n9e-webapi 和 n9e-server,6.x 之后合并成了一个,就是 n9e,这个模块既可以提供接口给前端调用,也可以提供告警引擎的能力。但是有的时候机房网络链路不好,或者有acl限制,很多 agent 没法连通服务端,此时就需要下沉部署方案。
# 1.1 中心汇聚式
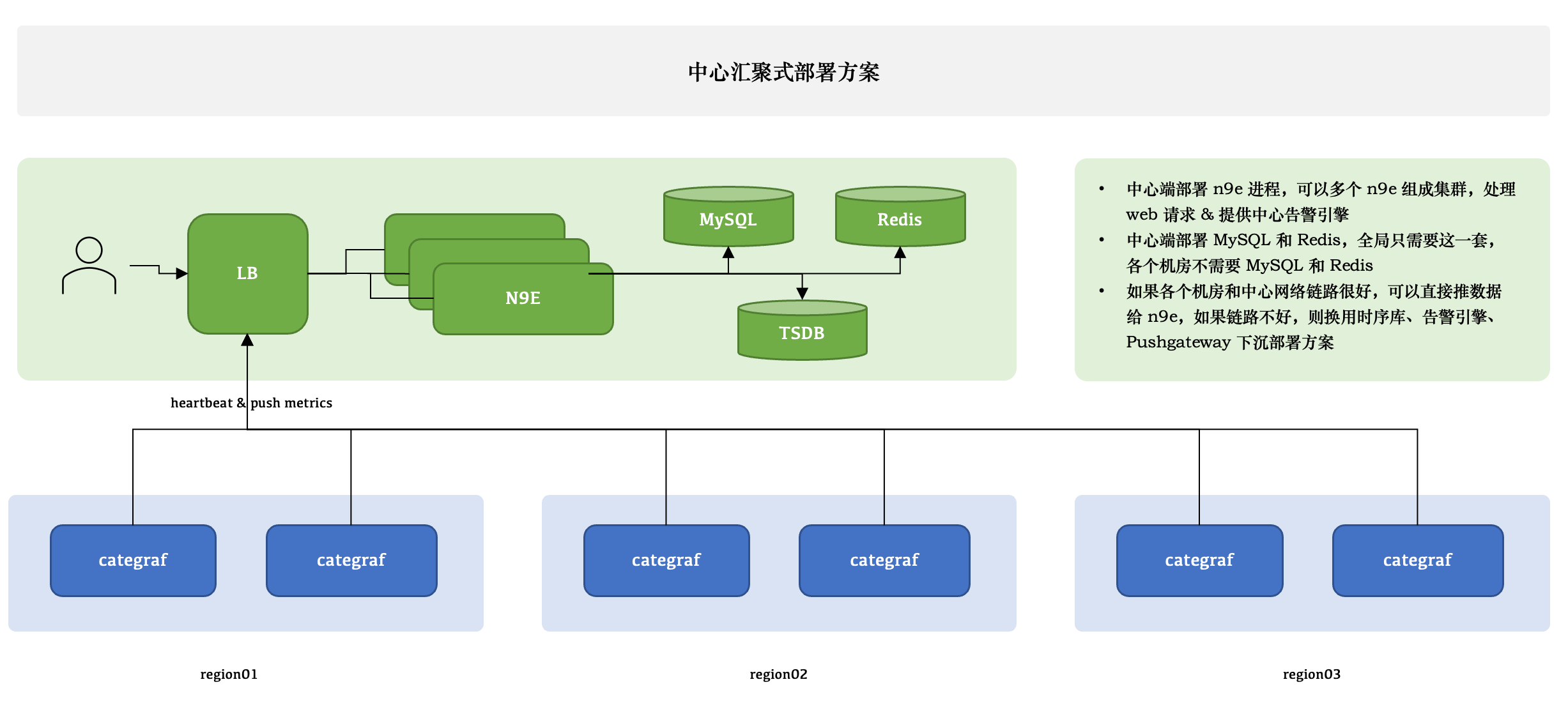
1个模块:n9e
可以部署多个 n9e 实例组成集群。
2 个存储:数据库、Redis
数据库可以使用 MySQL 或 Postgres,自己按需选用。
n9e 提供的是 HTTP 接口,前面负载均衡可以是 4 层或者 7 层。一般就选用 Nginx 就可以。
n9e 这个模块接收到数据之后,需要转发给后端的时序库,相关配置是:
[Pushgw]
LabelRewrite = true
[[Pushgw.Writers]]
Url = "http://127.0.0.1:9090/api/v1/write"
2
3
4
相当于是,虽然数据源可以在页面配置了,但是上报转发链路,还是需要在配置文件指定。
所有机房的 agent( 比如 Categraf、Telegraf、 Grafana-agent、Datadog-agent ),都直接推数据给 n9e,这个架构最为简单,维护成本最低。当然,前提是要求机房之间网络链路比较好,一般有专线。
# 1.2 边缘下沉式

三种不同的情形:
- A 机房和中心网络链路很好,Categraf 可以直接汇报数据给中心 n9e 模块;
- B 机房网络链路不好,就需要把时序库下沉部署,时序库下沉了,对应的告警引擎和转发网关也都要跟随下沉,这样数据不会跨机房传输,比较稳定。但是心跳还是需要往中心心跳,要不然在对象列表里看不到机器的 CPU、内存使用率。
- 接入一个已有的 Prometheus,数据采集没有走 Categraf,此时只需要把 Prometheus 作为数据源接入夜莺即可,可以在夜莺里看图、配告警规则,但是就是在对象列表里看不到,也不能使用告警自愈的功能,问题也不大,核心功能都不受影响。
边缘机房,下沉部署时序库、告警引擎、转发网关的时候,要注意:
告警引擎需要依赖数据库,因为要同步告警规则,转发网关也要依赖数据库,因为要注册对象到数据库里去,需要打通相关网络;
告警引擎和转发网关都不用Redis,所以无需为Redis打通网络。
# 2. 数据采集器
# 2.1 Categraf
简介
Categraf 是一个监控采集 Agent,类似 Telegraf、Grafana-Agent、Datadog-Agent,希望对所有常见监控对象提供监控数据采集能力,采用 All-in-one 的设计,不但支持指标采集,也希望支持日志和调用链路的数据采集。
来自快猫研发团队,和 Open-Falcon、Nightingale 的研发是一拨人。categraf 的代码托管在 github:https://github.com/flashcatcloud/categraf
对比
categraf 对比 telegraf、exporters、grafana-agent、datadog-agent :
telegraf 是 influxdb 生态的产品,因为 influxdb 是支持字符串数据的,所以 telegraf 采集的很多 field 是字符串类型,另外 influxdb 的设计,允许 labels 是非稳态结构,比如 result_code 标签,有时其 value 是 0,有时其 value 是 1,在 influxdb 中都可以接受。但是上面两点,在类似 prometheus 的时序库中,处理起来就很麻烦。
prometheus 生态有各种 exporters,但是设计逻辑都是一个监控类型一个 exporter,甚至一个实例一个 exporter,生产环境可能会部署特别多的 exporters,管理起来略麻烦。
grafana-agent import 了大量 exporters 的代码,没有裁剪,没有优化,没有最佳实践在产品上的落地,有些中间件,仍然是一个 grafana-agent 一个目标实例,管理起来也很不方便。
datadog-agent 确实是集大成者,但是大量代码是 python 的,整个发布包也比较大,有不少历史包袱,而且生态上是自成一派,和社区相对割裂。
categraf 确实又是一个轮子,categraf 希望:
- 支持 remote_write 写入协议,支持将数据写入 promethues、M3DB、VictoriaMetrics、InfluxDB
- 指标数据只采集数值,不采集字符串,标签维持稳态结构
- 采用 all-in-one 的设计,所有的采集工作用一个 agent 搞定,未来也可以把日志和 trace 的采集纳入 agent
- 纯 Go 代码编写,静态编译依赖少,容易分发,易于安装
- 尽可能落地最佳实践,不需要采集的数据无需采集,针对可能会对时序库造成高基数的问题在采集侧做出处理
- 常用的采集器,不但提供采集能力,还要整理出监控大盘和告警规则,用户可以直接导入使用
- 未来希望作为快猫 SaaS 产品的重要组成部分,引入快猫团队的研发力量持续迭代,当然,希望更多的公司、更多人研发人员参与共建,做成国内最开放、最好用的采集器
# 2.2 Telegraf
Telegraf 是 InfluxData 开源的一款采集器,可以采集操作系统、各种中间件的监控指标,采集目标列表:https://github.com/influxdata/telegraf/tree/master/plugins/inputs
Telegraf 是一个大一统的设计,即一个二进制可以采集CPU、内存、mysql、mongodb、redis、snmp等,不像Prometheus的exporter,每个监控对象一个exporter,管理起来略麻烦。一个二进制分发起来确实比较方便。
但是,Telegraf 主要是为 InfluxDB 设计的,采集的很多监控指标,标签部分可能不固定,比如 net_response 这个采集input插件,在成功的时候,会附一个标签:result=success,超时的时候,又会变成:result=timeout,对于InfluxDB的存储模型和使用方式来说,这样做是没问题的,但是大部分时序库都不喜欢这个玩法,时序库更喜欢标签是稳态的,因为标签是监控数据的唯一标识,如果标签发生变化,就相当于是新的监控数据了,这就有点恶心了。好在Telegraf提供了一些配置机制,可以把部分标签给干掉,只留那些稳定的标签,这样就舒服多了。上面这段话不理解也没关系,后面慢慢就有感触了。
调研Telegraf是希望把Telegraf作为夜莺的一种采集端程序使用,夜莺自身是有一个Agentd的,但是支持的采集内容有限,v5版本开始,拥抱Prometheus生态,故而可以和Prometheus生态的各类Exporter协同,但是Exporter是每类监控对象一个,不太方便管理,另外就是Exporter是pull模型,夜莺的设计中,会对监控对象做额外的产品支持,需要从监控数据中解析出监控对象,pull模型的exporter,直接由Prometheus进程来采集,数据压根就不会流经夜莺的服务端,所以夜莺无法感知到这些数据,更别提解析这些数据了。Telegraf有很多output插件,比如可以把采集到的监控数据输出给InfluxDB、OpenTSDB、Prometheus、Kafka等,夜莺只要实现比如OpenTSDB的接收数据的HTTP接口,就可以接收Telegraf推送的数据啦,这样数据就会先流经夜莺的服务端,在服务端做解析,提取监控对象,做一些Nodata判断等,与夜莺的生态良好的集成到了一起。
# 3. 时序数据库
夜莺监控的时序数据库分两种:
prometheus
夜莺可以直接使用prometheus的内置库做为时序数据库,适合数据量不大的场景(一般Prometheus 单机每秒接收 80 万个数据点,算是一个比较健康的容量上限)
victoriametrics
如果数据量比较大或者对时序库有分布式集群的需求,可以使用victoriametrics
# 3.1 Prometheus
Prometheus的基本架构:
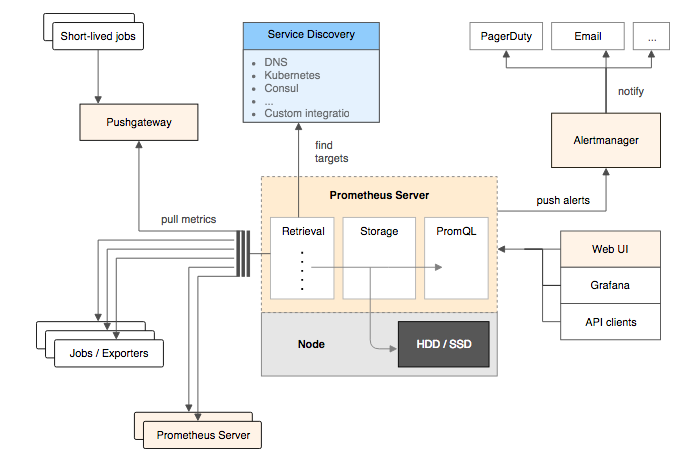
Prometheus Server
Prometheus Server是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。 Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Server需要对采集到的监控数据进行存储,Prometheus Server本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。最后Prometheus Server对外提供了自定义的PromQL语言,实现对数据的查询以及分析。
Prometheus Server内置的Express Browser UI,通过这个UI可以直接通过PromQL实现数据的查询以及可视化。
Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据,因此在大规模监控的情况下,可以通过联邦集群以及功能分区的方式对Prometheus Server进行扩展。
Exporters
Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
一般来说可以将Exporter分为2类:
- 直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
- 间接采集:间接采集,原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
AlertManager
在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由AlertManager进行管理。在AlertManager中我们可以与邮件,Slack等等内置的通知方式进行集成,也可以通过Webhook自定义告警处理方式。AlertManager即Prometheus体系中的告警处理中心。
PushGateway
由于Prometheus数据采集基于Pull模型进行设计,因此在网络环境的配置上必须要让Prometheus Server能够直接与Exporter进行通信。 当这种网络需求无法直接满足时,就可以利用PushGateway来进行中转。可以通过PushGateway将内部网络的监控数据主动Push到Gateway当中。而Prometheus Server则可以采用同样Pull的方式从PushGateway中获取到监控数据。
# 3.2 VictoriaMetrics
简介
VictoriaMetrics (opens new window) 架构简单,可靠性高,在性能,成本,可扩展性方面表现出色,社区活跃,且和 Prometheus 生态绑定紧密。如果单机版本的 Prometheus 无法在容量上满足贵司的需求,可以使用 VictoriaMetrics 作为时序数据库。
VictoriaMetrics 提供单机版 (opens new window)和集群版 (opens new window)。如果您的每秒写入数据点数小于100万(这个数量是个什么概念呢,如果只是做机器设备的监控,每个机器差不多采集200个指标,采集频率是10秒的话每台机器每秒采集20个指标左右,100万/20=5万台机器),VictoriaMetrics 官方默认推荐您使用单机版,单机版可以通过增加服务器的CPU核心数,增加内存,增加IOPS来获得线性的性能提升。且单机版易于配置和运维。
集群架构
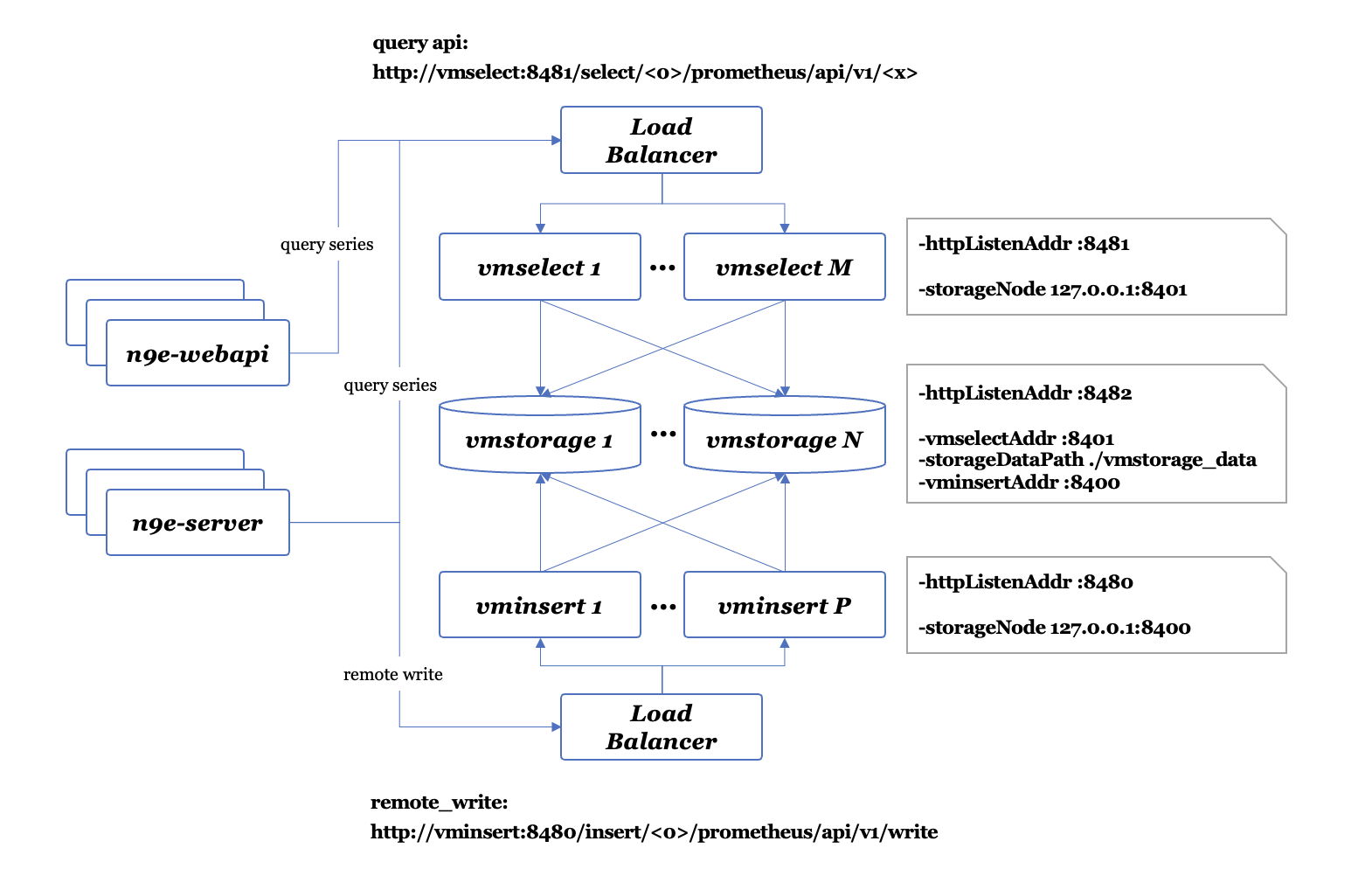
vmstorage、vminsert、vmselect 三者组合构成 VictoriaMetrics 的集群功能,三者都可以通过启动多个实例来分担承载流量,通过要在 vminsert 和 vmselect 前面架设负载均衡。
vmstorage 是数据存储模块
- 其数据保存在
-storageDataPath指定的目录中,默认为./vmstorage-data/,vmstorage 是有状态模块,删除 storage node 会丢失约1/N的历史数据(N 为集群中 vmstorage node 的节点数量)。增加 storage node,则需要同步修改 vminsert 和 vmselect 的启动参数,将新加入的storage node节点地址通过命令行参数-storageNode传入给vminsert和vmselect - vmstorage 启动后,会监听三个端口,分别是
-httpListenAddr :8482、-vminsertAddr :8400、-vmselectAddr :8401。端口8400负责接收来自 vminsert 的写入请求,端口8401负责接收来自 vmselect 的数据查询请求,端口8482则是 vmstorage 自身提供的 http api 接口
vminsert 接收来自客户端的数据写入请求,并负责转发到选定的vmstorage
- vminsert 接收到数据写入请求后,按照 jump consistent hash (opens new window) 算法,将数据转发到选定的某个vmstorage node 上。vminsert 本身是无状态模块,可以增加或者删除一个或多个实例,而不会造成数据的损失。vminsert 模块通过启动时的参数
-storageNode xxx,yyy,zzz来感知到整个 vmstorage 集群的完整 node 地址列表 - vminsert 启动后,会监听一个端口
-httpListenAddr :8480。该端口实现了prometheus remote_write协议,因此可以接收和解析通过remote_write协议写入的数据。不过要注意,VictoriaMetrics 集群版本具有多租户功能,因此租户ID会以如下形式出现在 API URL 中:http://vminsert:8480/insert/<account_id>/prometheus/api/v1/write - 更多 URL Format 可以参考 VictoriaMetrics官网 (opens new window)
vmselect 接收来自客户端的数据查询请求,并负责转发到所有的 vmstorage 查询结果,最后将结果 merge 后返回
- vmselect 启动后,会监听一个端口
-httpListenAddr :8481。该端口实现了prometheus query相关的接口。不过要注意,VictoriaMetrics 集群版本具有多租户功能,因此租户ID会以如下形式出现在 API URL 中:http://vminsert:8481/select/<account_id>/prometheus/api/v1/query。 - 更多 URL Format 可以参考 VictoriaMetrics官网 (opens new window)