 结构体定义
结构体定义
# 2. 结构体定义
# 2.1 类型字面值定义
复合类型的定义一般都是通过==类型字面值==的方式来进行的,作为复合类型之一的结构体类型也不例外,典型的结构体类型的定义形式:
type T struct {
Field1 T1
Field2 T2
... ...
FieldN Tn
}
2
3
4
5
6
对现实世界的书进行抽象的情况,其实用结构体类型就可以实现。通过聚合其他类型字段,结构体类型展现出强大而灵活的抽象能力。
package book
type Book struct {
Title string // 书名
Pages int // 书的页数
Indexes map[string]int // 书的索引
}
2
3
4
5
6
7
根据这个定义,我们会得到一个名为 Book的结构体类型,定义中 struct 关键字后面的大括号包裹的内容就是一个类型字面值。我们看到这个类型字面值由若干个字段(field)聚合而成,每个字段有自己的名字与类型,并且在一个结构体中,每个字段的名字应该都是唯一的。
**首字母大写:**Go 用标识符名称的首字母大小写来判定这个标识符是否为导出标识符。所以,这里的类型 Book 以及它的各个字段都是导出标识符。这样,只要其他包导入了包 book,我们就可以在这些包中直接引用类型名 Book,也可以通过 Book 类型变量引用 Name、Pages 等字段,就像下面代码中这样:
import ".../book" var b book.Book b.Title = "The Go Programming Language" b.Pages = 8001
2
3
4
5如果结构体类型只在它定义的包内使用,那么我们可以将类型名的首字母小写;如果你不想将结构体类型中的某个字段暴露给其他包,那么我们同样可以把这个字段名字的首字母小写。
还可以用空标识符“_”作为结构体类型定义中的字段名称。这样以空标识符为名称的字段,不能被外部包引用,甚至无法被结构体所在的包使用。
# 2.2 空结构体定义
没有包含任何字段的结构体类型。
type Empty struct{} // Empty是一个不包含任何字段的空结构体类型
# 2.2.1 空结构体类型作用
var s Empty
println(unsafe.Sizeof(s)) // 0
2
空结构体类型变量的内存占用为 0。基于空结构体类型内存零开销这样的特性,在日常 Go 开发中会经常使用空结构体类型元素,作为一种“事件”信息进行 Goroutine 之间的通信。
var c = make(chan Empty) // 声明一个元素类型为Empty的channel
c<-Empty{} // 向channel写入一个“事件”
2
这种以空结构体为元素类建立的 channel,是目前能实现的、内存占用最小的 Goroutine 间通信方式。
# 2.3 使用其他结构体作为自定义结构体中字段的类型
使用其他结构体作为自定义结构体中字段的类型。
// 结构体类型 Book 的字段 Author 的类型,就是另外一个结构体类型 Person:
type Person struct {
Name string
Phone string
Addr string
}
type Book struct {
Title string
Author Person
... ...
}
// 如果要访问 Book 结构体字段 Author 中的 Phone 字段,可以这样操作:
var book Book
println(book.Author.Phone)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
也可以无需提供字段的名字,只需要使用其类型就可以了。
type Book struct {
Title string
Person
... ...
}
2
3
4
5
以这种方式定义的结构体字段,我们叫做==嵌入字段(Embedded Field)==。我们也可以将这种字段称为==匿名字段==,或者把类型名看作是这个字段的名字。
// 如果要访问 Person 中的 Phone 字段,可以通过下面两种方式进行:
var book Book
println(book.Person.Phone) // 将类型名当作嵌入字段的名字
println(book.Phone) // 支持直接访问嵌入字段所属类型中字段
2
3
4
注意:在结构体类型 T 的定义中不可以包含类型为 T 的字段,Go 语言不支持在结构体类型定义中,递归地放入其自身类型字段的定义方式。
type T struct {
t T
... ...
} // invalid recursive type T
// 下面这两个结构体类型 T1 与 T2 的定义也存在递归的情况,所以这也是不合法的。
type T1 struct {
t2 T2
}
type T2 struct {
t1 T1
}
2
3
4
5
6
7
8
9
10
11
12
13
14
但是可以拥有自身类型的指针类型、以自身类型为元素类型的切片类型,以及以自身类型作为 value 类型的 map 类型的字段。
type T struct {
t *T // ok
st []T // ok
m map[string]T // ok
}
2
3
4
5
# 2.4 结构体变量的声明和初始化
# 2.4.1 结构体变量声明
可以使用标准变量声明语句,或者是短变量声明语句声明一个结构体类型的变量:
type Book struct {
...
}
var book Book
var book = Book{}
book := Book{}
2
3
4
5
6
7
结构体类型通常是对真实世界复杂事物的抽象,这和简单的数值、字符串、数组 / 切片等类型有所不同,结构体类型的变量通常都要被赋予适当的初始值后,才会有合理的意义。
# 2.4.2 零值初始化
结构体类型的零值变量,通常不具有或者很难具有合理的意义。
var book Book // book为零值结构体变量
零值初始化作用:
如果一种类型采用零值初始化得到的零值变量,是有意义的,而且是直接可用的,这种类型为==“零值可用”==类型。可以说,定义零值可用类型是简化代码、改善开发者使用体验的一种重要的手段。
在 Go 语言标准库和运行时的代码中,有很多践行“零值可用”理念的好例子:
- sync 包的 Mutex 类型了。Mutex 是 Go 标准库中提供的、用于多个并发 Goroutine 之间进行同步的互斥锁。
var mu sync.Mutex
mu.Lock()
mu.Unlock()
2
3
Go 标准库的设计者很贴心地将 sync.Mutex 结构体的零值状态,设计为可用状态,这样开发者便可直接基于零值状态下的 Mutex 进行 lock 与 unlock 操作,而且不需要额外显式地对它进行初始化操作了。
- Go 标准库中的 bytes.Buffer 结构体类型
var b bytes.Buffer
b.Write([]byte("Hello, Go"))
fmt.Println(b.String()) // 输出:Hello, Go
2
3
不需要对 bytes.Buffer 类型的变量 b 进行任何显式初始化,就可以直接通过处于零值状态的变量 b,调用它的方法进行写入和读取操作。
# 2.4.3 复合字面值初始化
在日常开发中,对结构体类型变量进行显式初始化的最常用方法就是使用复合字面值。
最简单的对结构体变量进行显式初始化的方式,就是按顺序依次给每个结构体字段进行赋值:
type Book struct {
Title string // 书名
Pages int // 书的页数
Indexes map[string]int // 书的索引
}
var book = Book{"The Go Programming Language", 700, make(map[string]int)}
2
3
4
5
6
7
我们依然可以用这种方法给结构体的每一个字段依次赋值,但这种方法也有很多问题:
首先,当结构体类型定义中的字段顺序发生变化,或者字段出现增删操作时,我们就需要手动调整该结构体类型变量的显式初始化代码,让赋值顺序与调整后的字段顺序一致。
其次,当一个结构体的字段较多时,这种逐一字段赋值的方式实施起来就会比较困难,而且容易出错,开发人员需要来回对照结构体类型中字段的类型与顺序,谨慎编写字面值表达式。
最后,一旦结构体中包含非导出字段,那么这种逐一字段赋值的方式就不再被支持了,编译器会报错:
type T struct { F1 int F2 string f3 int F4 int F5 int } var t = T{11, "hello", 13} // 错误:implicit assignment of unexported field 'f3' in T literal 或 var t = T{11, "hello", 13, 14, 15} // 错误:implicit assignment of unexported field 'f3' in T literal1
2
3
4
5
6
7
8
9
10
11事实上,Go 语言并不推荐我们按字段顺序对一个结构体类型变量进行显式初始化,甚至 Go 官方还在提供的 go vet 工具中专门内置了一条检查规则:“composites” (opens new window),用来静态检查代码中结构体变量初始化是否使用了这种方法,一旦发现,就会给出警告。
Go 推荐使用==“field:value”形式的复合字面值==,对结构体类型变量进行显式初始化。
这种方式**可以降低结构体类型使用者和结构体类型设计者之间的耦合,**这也是 Go 语言的惯用法。
var t = T{
F2: "hello",
F1: 11,
F4: 14,
}
2
3
4
5
使用这种**“field:value”**形式的复合字面值对结构体类型变量进行初始化,非常灵活。
和之前的顺序复合字面值形式相比,“field:value”形式字面值中的字段可以以任意次序出现。
未显式出现在字面值中的结构体字段(比如上面例子中的 F5)将采用它对应类型的零值。
复合字面值作为结构体类型变量初值被广泛使用,即便结构体采用类型零值时,我们也会使用复合字面值的形式:
t := T{}
# 2.4.4 特定的构造函数初始化
使用特定的构造函数创建并初始化结构体变量。
在 Go 标准库中有很多例子,其中 time.Timer 这个结构体就是一个典型,它的定义如下:
// $GOROOT/src/time/sleep.go
type runtimeTimer struct {
pp uintptr
when int64
period int64
f func(interface{}, uintptr)
arg interface{}
seq uintptr
nextwhen int64
status uint32
}
type Timer struct {
C <-chan Time
r runtimeTimer
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Timer 结构体中包含了一个非导出字段 r,r 的类型为另外一个结构体类型 runtimeTimer。这个结构体更为复杂,而且我们一眼就可以看出来,这个 runtimeTimer 结构体不是零值可用的,那我们在创建一个 Timer 类型变量时就没法使用显式复合字面值的方式了。这个时候,Go 标准库提供了一个 Timer 结构体专用的构造函数 NewTimer,它的实现如下:
// $GOROOT/src/time/sleep.go func NewTimer(d Duration) *Timer { c := make(chan Time, 1) t := &Timer{ C: c, r: runtimeTimer{ when: when(d), f: sendTime, arg: c, }, } startTimer(&t.r) return t }1
2
3
4
5
6
7
8
9
10
11
12
13
14NewTimer 这个函数只接受一个表示定时时间的参数 d,在经过一个复杂的初始化过程后,它返回了一个处于可用状态的 Timer 类型指针实例。
像这类通过专用构造函数进行结构体类型变量创建、初始化的例子还有很多,它们的专用构造函数大多都符合这种模式:
func NewT(field1, field2, ...) *T {
... ...
}
2
3
NewT 是结构体类型 T 的专用构造函数,它的参数列表中的参数通常与 T 定义中的导出字段相对应,返回值则是一个 T 指针类型的变量。T 的非导出字段在 NewT 内部进行初始化,一些需要复杂初始化逻辑的字段也会在 NewT 内部完成初始化。这样,我们只要调用 NewT 函数就可以得到一个可用的 T 指针类型变量了。
# 2.5 结构体类型的内存布局
Go 结构体类型是既数组类型之后,第二个将它的元素(结构体字段)一个接着一个以“平铺”形式,存放在一个连续内存块中的。
结构体类型 T 理想的内存布局:
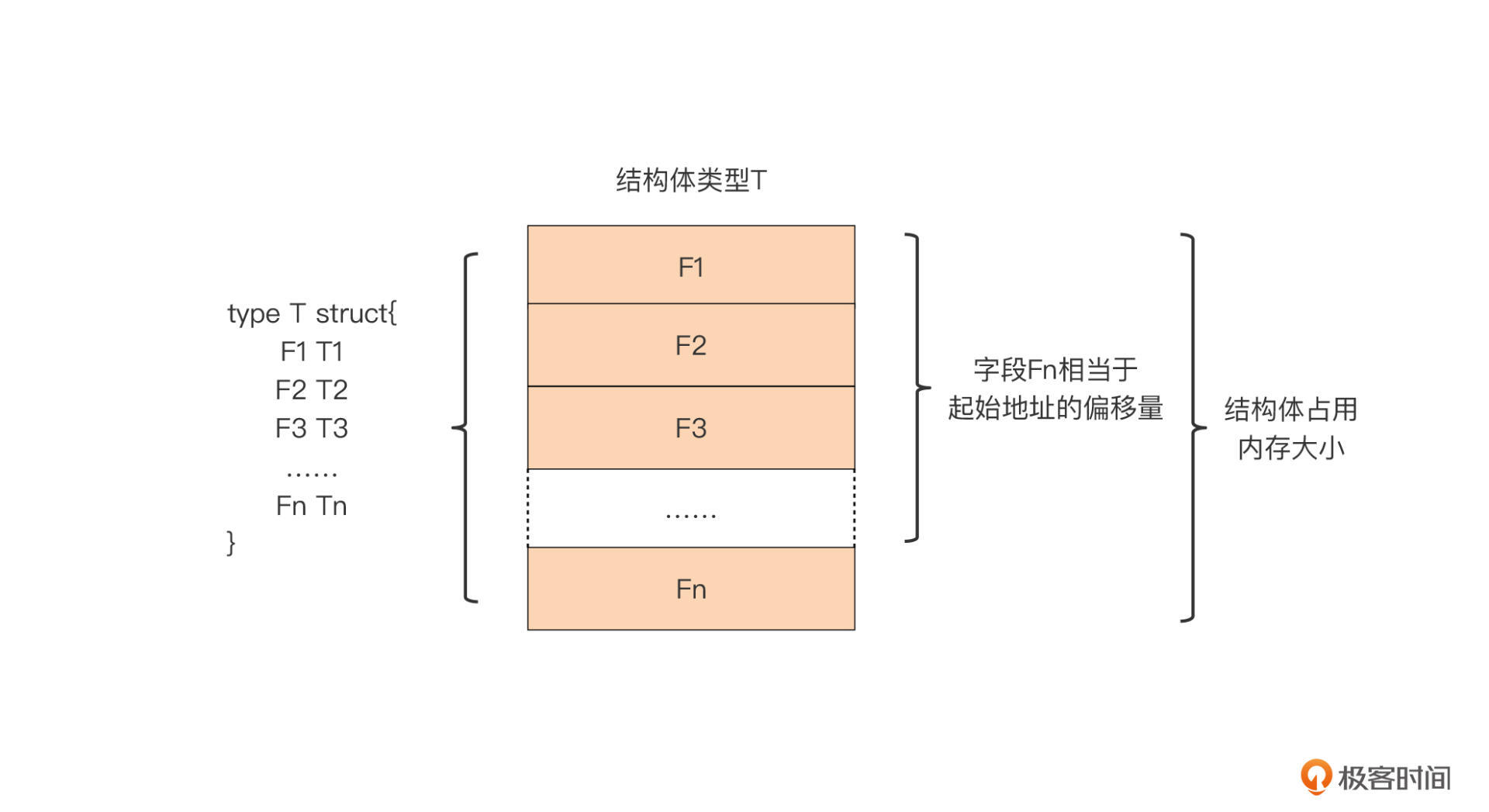
结构体类型 T 在内存中布局是非常紧凑的,Go 为它分配的内存都用来存储字段了,没有被 Go 编译器插入的额外字段。
我们可以借助标准库 unsafe 包提供的函数,获得结构体类型变量占用的内存大小,以及它每个字段在内存中相对于结构体变量起始地址的偏移量:
var t T
unsafe.Sizeof(t) // 结构体类型变量占用的内存大小
unsafe.Offsetof(t.Fn) // 字段Fn在内存中相对于变量t起始地址的偏移量
2
3
结构体类型 T 真实的内存布局:
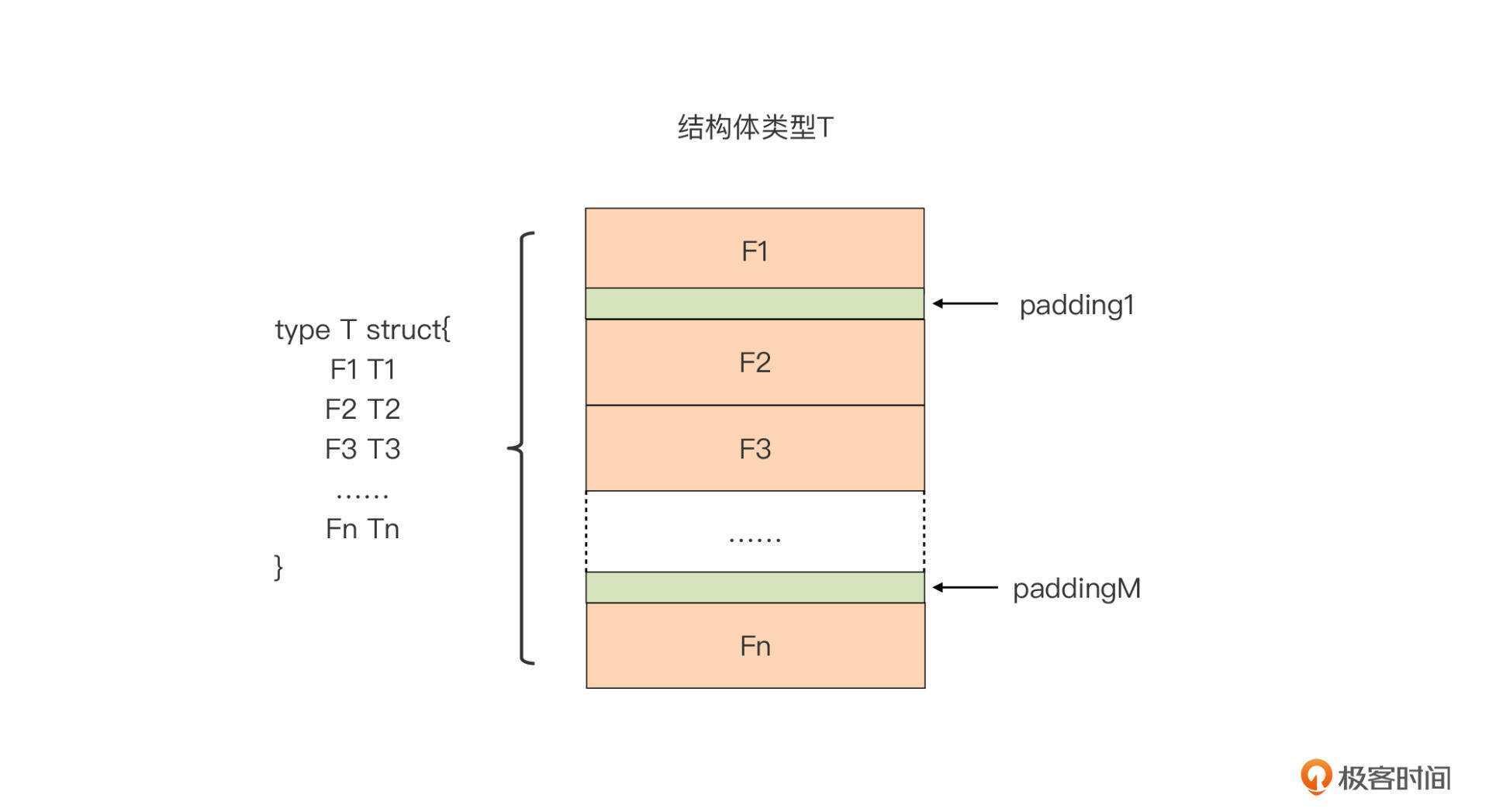
在真实情况下,虽然 Go 编译器没有在结构体变量占用的内存空间中插入额外字段,但结构体字段实际上可能并不是紧密相连的,中间可能存在“缝隙”。
这些“缝隙”同样是结构体变量占用的内存空间的一部分,它们是 Go 编译器插入的“填充物(Padding)”。
Go 编译器在结构体的字段间插入“填充物”的目的:
这其实是**内存对齐的要求。**内存对齐,指的就是各种内存对象的内存地址不是随意确定的,必须满足特定要求。
- 对于各种基本数据类型来说,它的变量的内存地址值必须是其类型本身大小的整数倍,比如,一个 int64 类型的变量的内存地址,应该能被 int64 类型自身的大小,也就是 8 整除;一个 uint16 类型的变量的内存地址,应该能被 uint16 类型自身的大小,也就是 2 整除。
- 对于结构体类型这样的复合数据类型,内存对齐实际上没有这么严格。对于结构体而言,它的变量的内存地址,只要是它最长字段长度与系统对齐系数两者之间较小的那个的整数倍就可以了。但对于结构体类型来说,还要让它每个字段的内存地址都严格满足内存对齐要求。
type T1 struct {
b byte
i int64
u uint16
}
2
3
4
5
6
计算一下这个结构体类型 T 的对齐系数:

整个计算过程分为两个阶段:
第一个阶段:对齐结构体的各个字段
首先,第一个字段 b 是长度 1 个字节的 byte 类型变量,这样字段 b 放在任意地址上都可以被 1 整除,所以我们说它是天生对齐的。我们用一个 sum 来表示当前已经对齐的内存空间的大小,这个时候 sum=1;
接下来,我们看第二个字段 i,它是一个长度为 8 个字节的 int64 类型变量。按照内存对齐要求,它应该被放在可以被 8 整除的地址上。但是,如果把 i 紧邻 b 进行分配,当 i 的地址可以被 8 整除时,b 的地址就无法被 8 整除。这个时候,我们需要在 b 与 i 之间做一些填充,使得 i 的地址可以被 8 整除时,b 的地址也始终可以被 8 整除,于是我们在 i 与 b 之间填充了 7 个字节,此时此刻 sum=1+7+8;
再下来,我们看第三个字段 u,它是一个长度为 2 个字节的 uint16 类型变量,按照内存对其要求,它应该被放在可以被 2 整除的地址上。有了对其的 i 作为基础,我们现在知道将 u 与 i 相邻而放,是可以满足其地址的对齐要求的。i 之后的那个字节的地址肯定可以被 8 整除,也一定可以被 2 整除。于是我们把 u 直接放在 i 的后面,中间不需要填充,此时此刻,sum=1+7+8+2。
第二个阶段:对齐整个结构体
结构体的内存地址为 min(结构体最长字段的长度,系统内存对齐系数)的整数倍,那么这里结构体 T 最长字段为 i,它的长度为 8,而 64bit 系统上的系统内存对齐系数一般为 8,两者相同,我们取 8 就可以了。那么整个结构体的对齐系数就是 8。
这个时候问题就来了!为什么上面的示意图还要在结构体的尾部填充了 6 个字节呢?
我们说过结构体 T 的对齐系数是 8,那么我们就要保证每个结构体 T 的变量的内存地址,都能被 8 整除。如果我们只分配一个 T 类型变量,不再继续填充,也可能保证其内存地址为 8 的倍数。
但如果考虑我们分配的是一个元素为 T 类型的数组,比如下面这行代码,我们虽然可以保证 T[0]这个元素地址可以被 8 整除,但能保证 T[1]的地址也可以被 8 整除吗?
var array [10]T1我们知道,数组是元素连续存储的一种类型,元素 T[1]的地址为 T[0]地址 +T 的大小 (18),显然无法被 8 整除,这将导致 T[1]及后续元素的地址都无法对齐,这显然不能满足内存对齐的要求。
问题的根源在哪里呢?问题就在于 T 的当前大小为 18,这是一个不能被 8 整除的数值,如果 T 的大小可以被 8 整除,那问题就解决了。于是我们才有了最后一个步骤,我们从 18 开始向后找到第一个可以被 8 整除的数字,也就是将 18 圆整到 8 的倍数上,我们得到 24,我们将 24 作为类型 T 最终的大小就可以了。
为什么会出现内存对齐的要求呢?这是出于对处理器存取数据效率的考虑。在早期的一些处理器中,比如 Sun 公司的 Sparc 处理器仅支持内存对齐的地址,如果它遇到没有对齐的内存地址,会引发段错误,导致程序崩溃。我们常见的 x86-64 架构处理器虽然处理未对齐的内存地址不会出现段错误,但数据的存取性能也会受到影响。
Go 语言中结构体类型的大小受内存对齐约束的影响。这样一来,不同的字段排列顺序也会影响到“填充字节”的多少,从而影响到整个结构体大小。
比如下面两个结构体类型表示的抽象是相同的,但正是因为字段排列顺序不同,导致它们的大小也不同:
type T struct {
b byte
i int64
u uint16
}
type S struct {
b byte
u uint16
i int64
}
func main() {
var t T
println(unsafe.Sizeof(t)) // 24
var s S
println(unsafe.Sizeof(s)) // 16
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
所以,在日常定义结构体时,一定要注意结构体中字段顺序,尽量合理排序,降低结构体对内存空间的占用。
有些时候,为了保证某个字段的内存地址有更为严格的约束,我们也会做主动填充。
比如 runtime 包中的 mstats 结构体定义就采用了主动填充:
// $GOROOT/src/runtime/mstats.go
type mstats struct {
... ...
// Add an uint32 for even number of size classes to align below fields
// to 64 bits for atomic operations on 32 bit platforms.
_ [1 - _NumSizeClasses%2]uint32 // 这里做了主动填充
last_gc_nanotime uint64 // last gc (monotonic time)
last_heap_inuse uint64 // heap_inuse at mark termination of the previous GC
... ...
}
2
3
4
5
6
7
8
9
10
11
12
# 2.6 基本实例化(方法1)
只有当结构体实例化时,才会真正地分配内存,也就是必须实例化后才能使用结构体的字段。
结构体本身也是一种类型,我们可以像声明内置类型一样使用 var 关键字声明结构体类型。
package main
import "fmt"
type person struct {
name string
city string
age int
}
func main() {
var p1 person
p1.name = "张三"
p1.city = "北京"
p1.age = 18
fmt.Printf("p1=%v\n", p1) // p1={张三 北京 18}
fmt.Printf("p1=%#v\n", p1) // p1=main.person{name:"张三", city:"北京", age:18}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 2.7 new实例化(方法2)
还可以通过使用 new 关键字对结构体进行实例化,得到的是结构体的地址。
package main
import "fmt"
type person struct {
name string
city string
age int
}
func main() {
var p2 = new(person)
p2.name = "张三"
p2.city = "北京"
p2.age = 20
fmt.Printf("p2=%#v\n", p2) //p2=&main.person{name:"张三", city:"北京", age:20}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
从打印的结果中我们可以看出 p2 是一个结构体指针。
注意:在 Golang 中支持对结构体指针直接使用.来访问结构体的成员。p2.name = "张三" 其实在底层是 (*p2).name = "张三"。
# 2.8 键值对初始化(方法3)
package main
import "fmt"
type person struct {
name string
city string
age int
}
func main() {
p4 := person{
name: "zhangsan",
city: "北京",
age: 18,
}
// p4=main.person{name:"zhangsan", city:"北京", age:18}
fmt.Printf("p4=%#v\n", p4)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 2.9 自定义新类型
# 2.9.1 类型定义(Type Definition)
最常用的类型定义方法。在这种方法中,使用关键字type 来定义一个新类型 T。
type T S // 定义一个新类型T
S 可以是任何一个已定义的类型,包括 Go 原生类型,或者是其他已定义的自定义类型。
type T1 int
type T2 T1
2
底层类型。如果一个新类型是基于某个 Go 原生类型定义的,那么我们就叫 Go 原生类型为新类型的底层类型(Underlying Type)。
新类型 T1 是基于 Go 原生类型 int 定义的新自定义类型,而新类型 T2 则是基于刚刚定义的类型 T1,定义的新类型。
类型 int 就是类型 T1 的底层类型,T2 类型的底层类型就是 T1 的底层类型,那么 T2 的底层类型也是类型 int。
底层类型被用来判断两个类型本质上是否相同(Identical)。
本质上相同的两个类型,它们的变量可以通过显式转型进行相互赋值,相反,如果本质上是不同的两个类型,它们的变量间连显式转型都不可能,更不要说相互赋值了。
type T1 int
type T2 T1
type T3 string
func main() {
var n1 T1
var n2 T2 = 5
n1 = T1(n2) // ok
var s T3 = "hello"
n1 = T1(s) // 错误:cannot convert s (type T3) to type T1
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 2.9.2 类型别名(Type Alias)
这种类型定义方式通常用在项目的渐进式重构,还有对已有包的二次封装方面,它的形式是这样的:
type T = S // type alias
使用 string 类型变量 s 给 T 类型变量 t 赋值的动作,实质上就是同类型赋值。
type T = string
var s string = "hello"
var t T = s // ok
fmt.Printf("%T\n", t) // string
2
3
4
5