 监控系统
监控系统
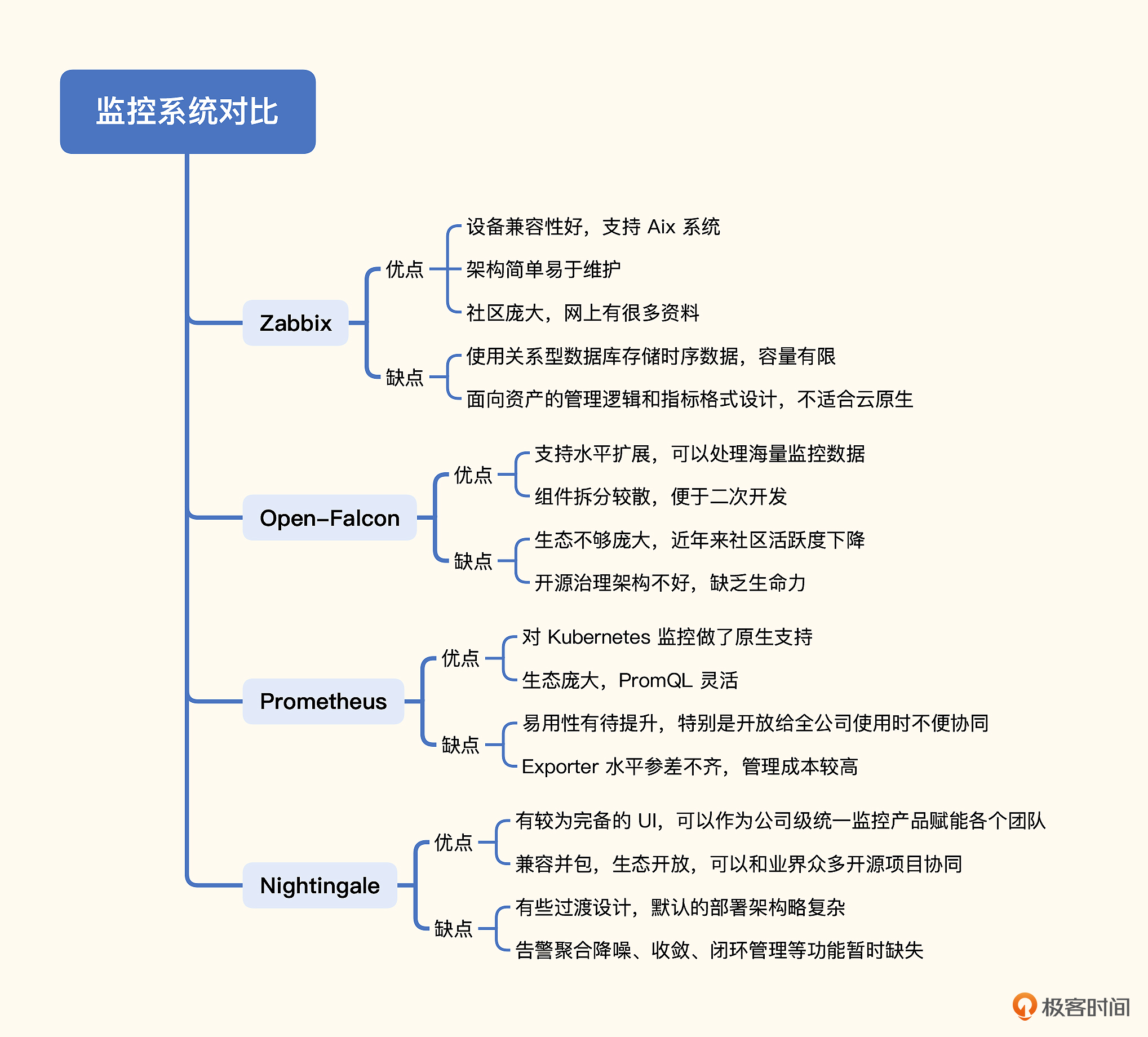
# 1. 开源监控软件对比
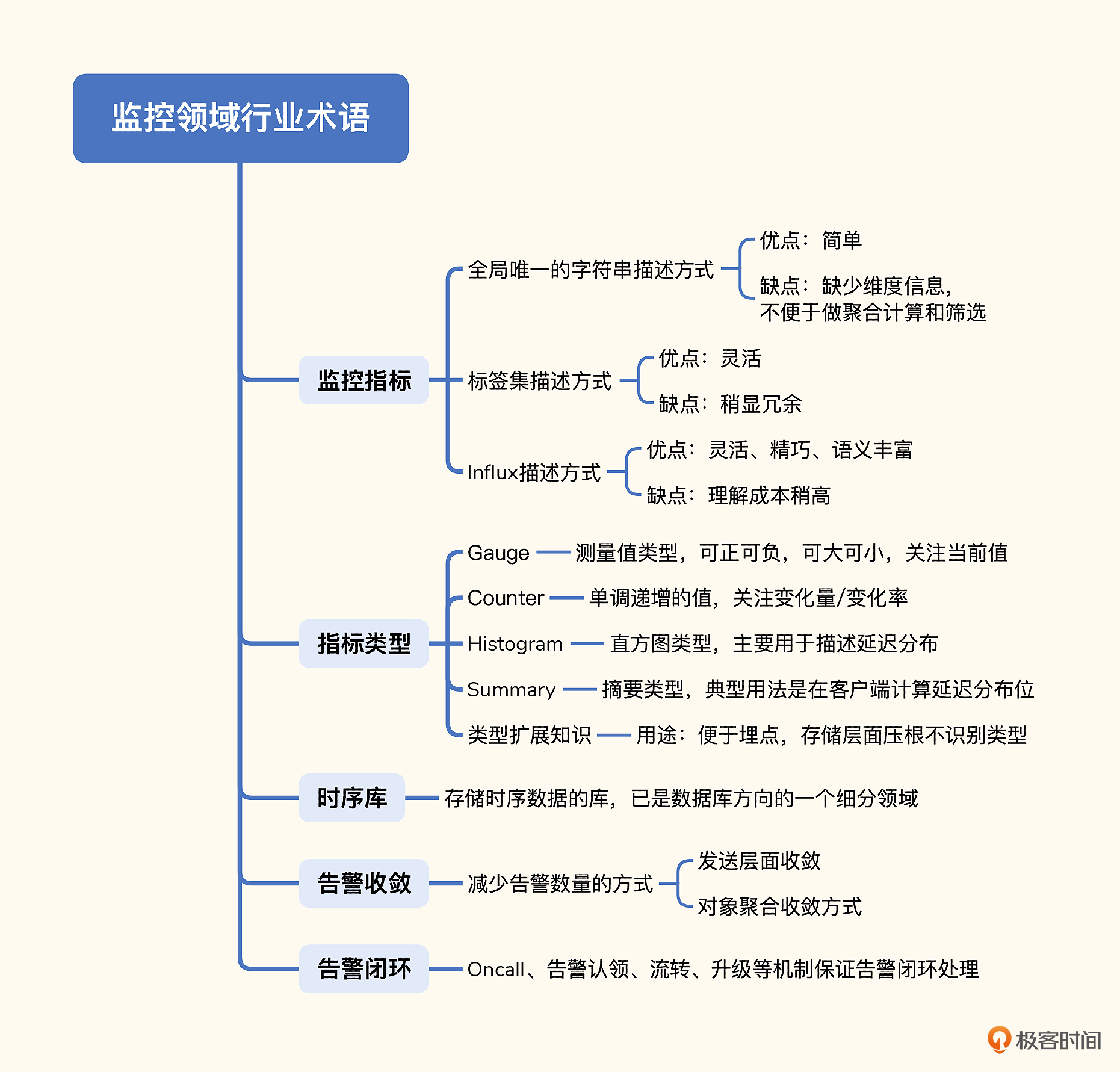
# 2. 监控基本概念
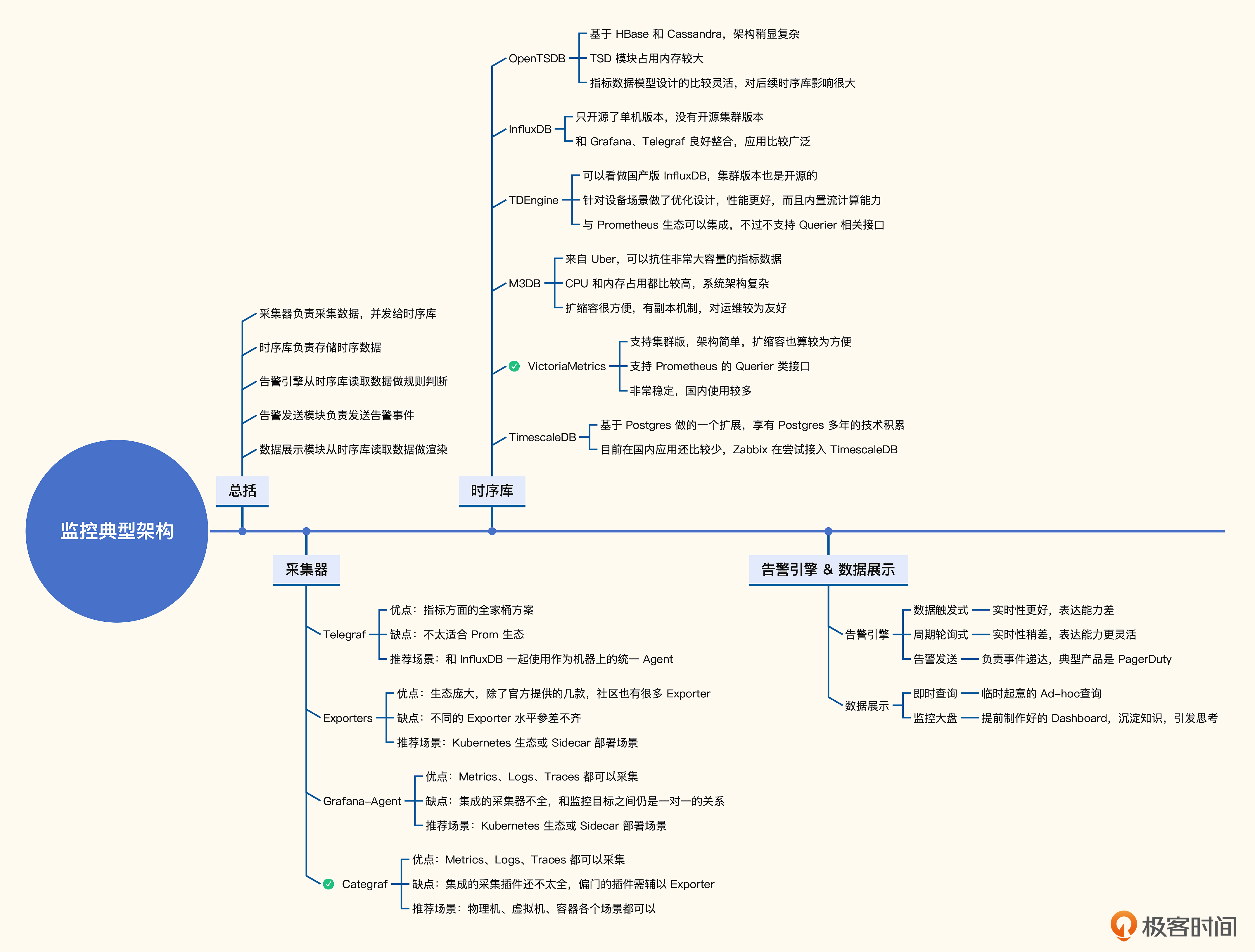
# 3. 监控系统典型架构
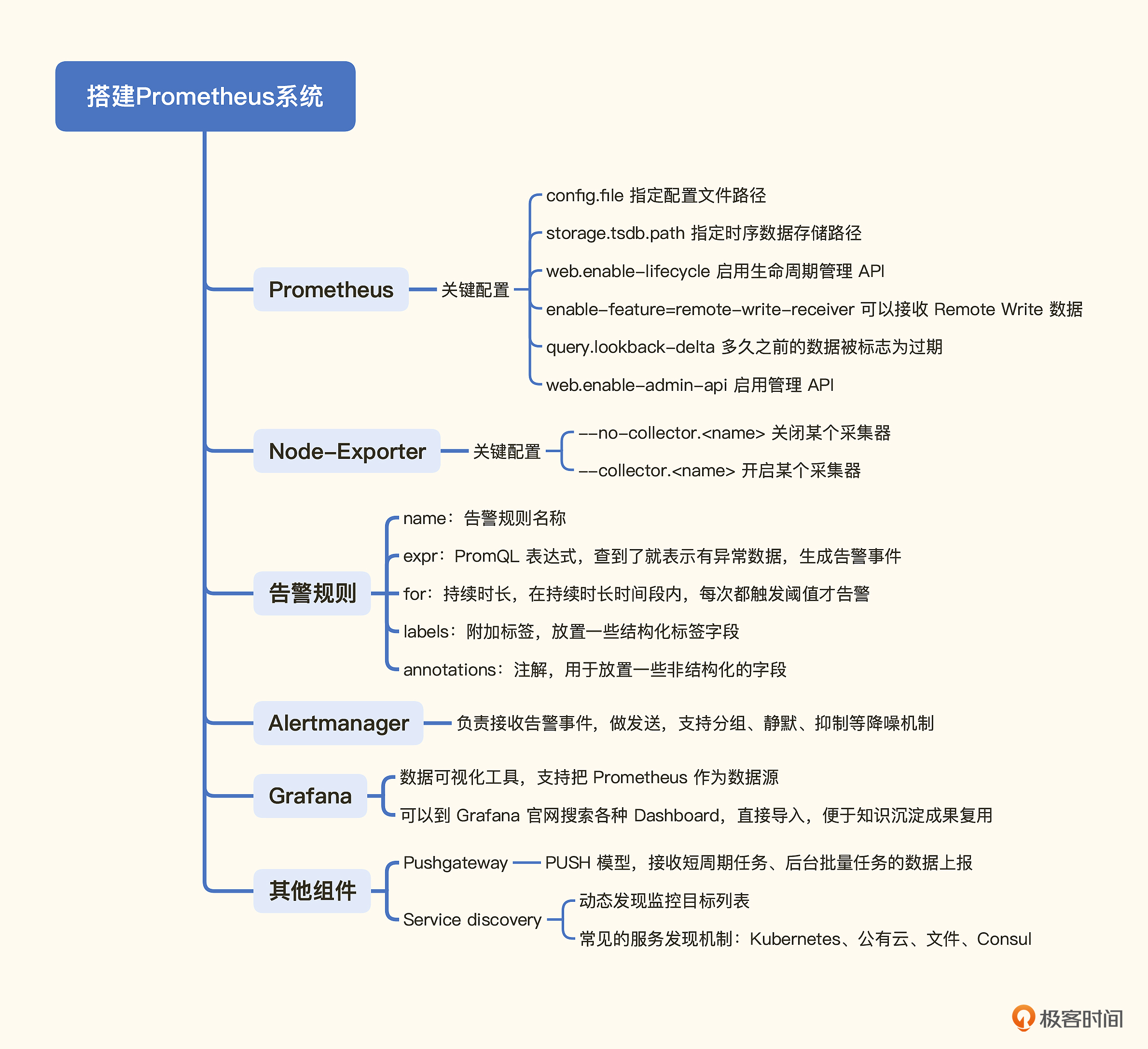
# 4. 搭建prometheus
Prometheus 单机容量上限是多少?根据我的经验,每秒接收 80 万个数据点,算是一个比较健康的上限,一开始也无需用一台配置特别高的机器,随着数据量的增长,可以再升级硬件的配置。当然,如果想要硬件方便升配,就需要借助虚拟机或容器,同时需要使用分布式块存储。 每秒接收 80 万个数据点是个什么概念呢?每台机器每个周期大概采集 200 个系统级指标,比如 CPU、内存、磁盘等相关的指标。假设采集频率是 10 秒,平均每秒上报 20 个数据点,可以支持同时监控的机器量是 4 万台。
# 5. prometheus关键设计

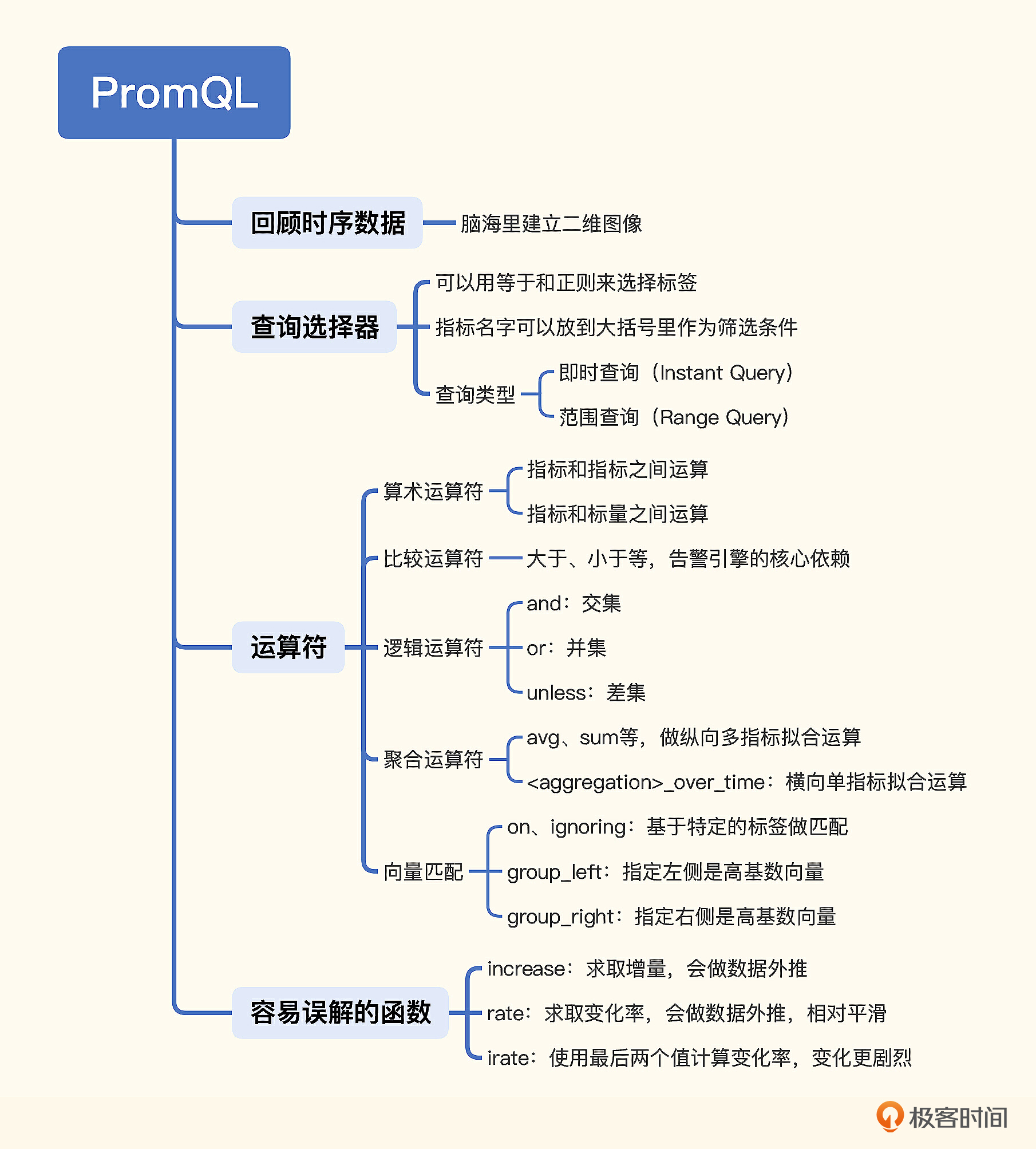
# 6. promQL
# 7. Prometheus存储容量问题

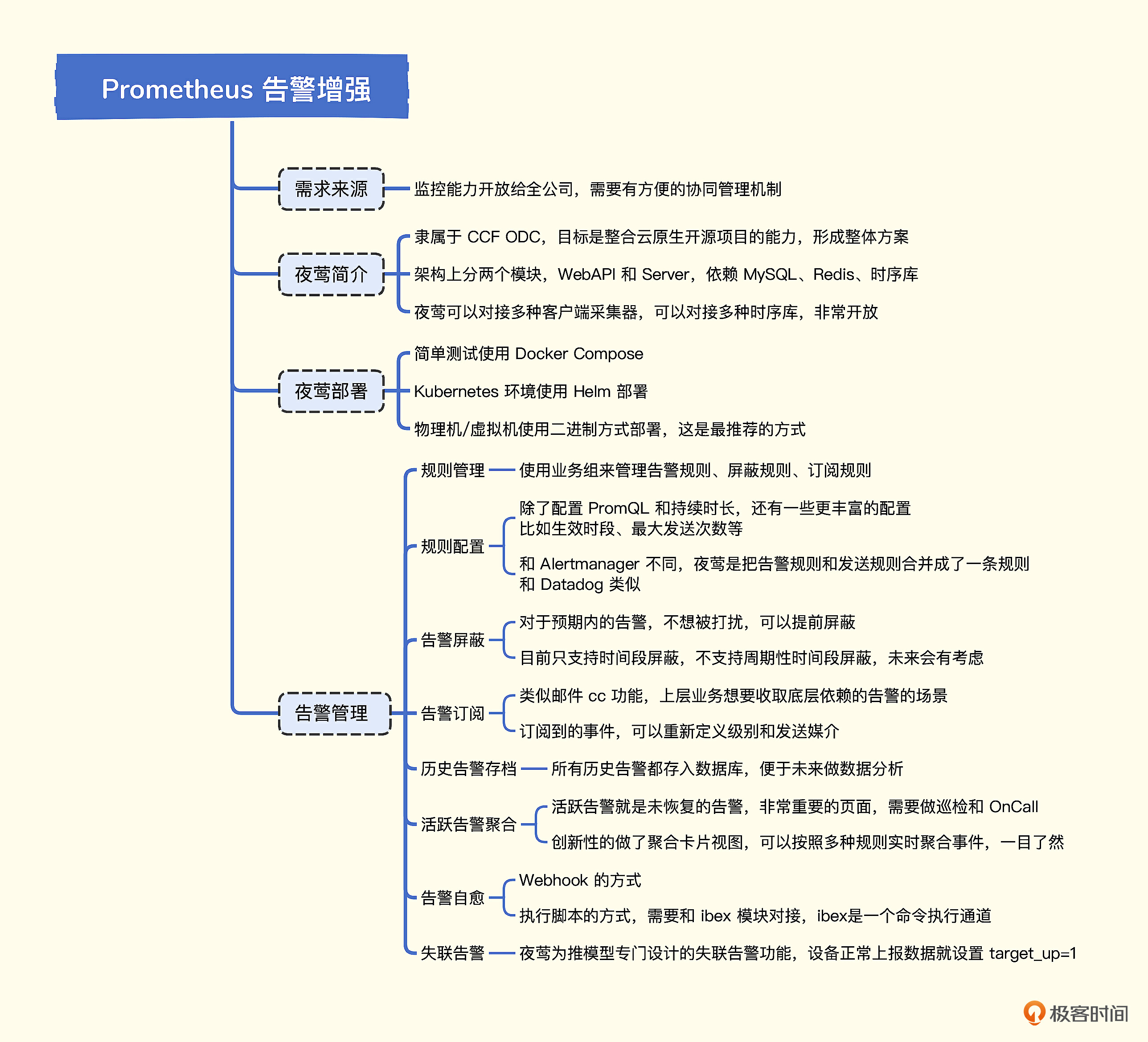
# 8. Prometheus 告警管理(Nightingale)
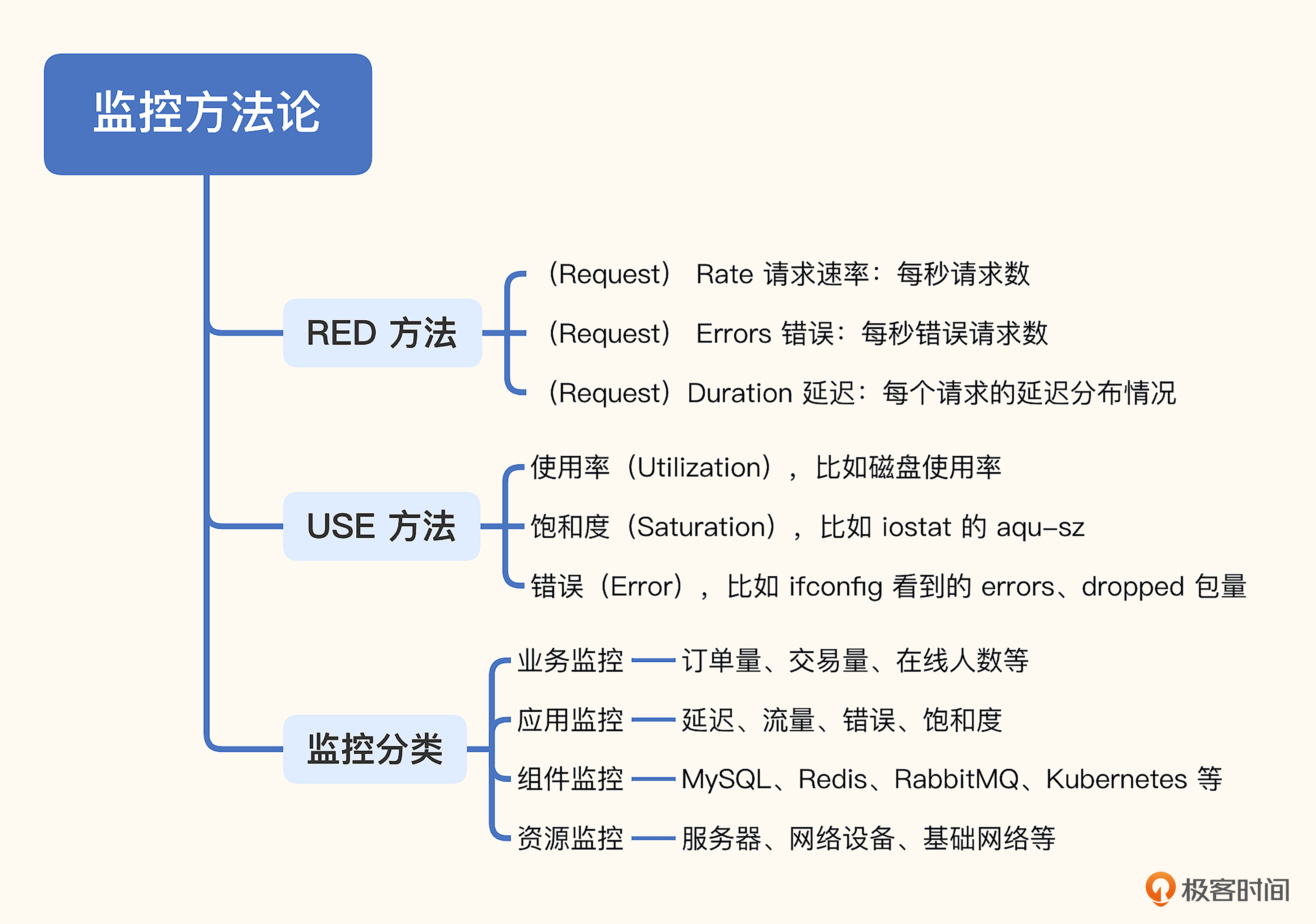
# 9. 监控方法论
# Google 的四个黄金指标
主要是服务监控,四个指标分别是延迟、流量、错误和饱和度。
延迟:服务请求所花费的时间,比如用户获取商品列表页面调用的某个接口,花费 30 毫秒。这个指标需要区分成功请求和失败请求,因为失败的请求可能会立刻返回,延迟很小,会扰乱正常的请求延迟数据。
流量:HTTP 服务的话就是每秒 HTTP 请求数,RPC 服务的话就是每秒 RPCCall 的数量,如果是数据库,可能用数据库系统的事务量来作为流量指标。
错误:请求失败的速率,即每秒有多少请求失败,比如 HTTP 请求返回了 500 错误码,说明这个请求是失败的,或者虽然返回的状态码是 200,但是返回的内容不符合预期,也认为是请求失败。
饱和度:描述应用程序有多“满”,或者描述受限的资源,比如 CPU 密集型应用,CPU 使用率就可以作为饱和度指标。
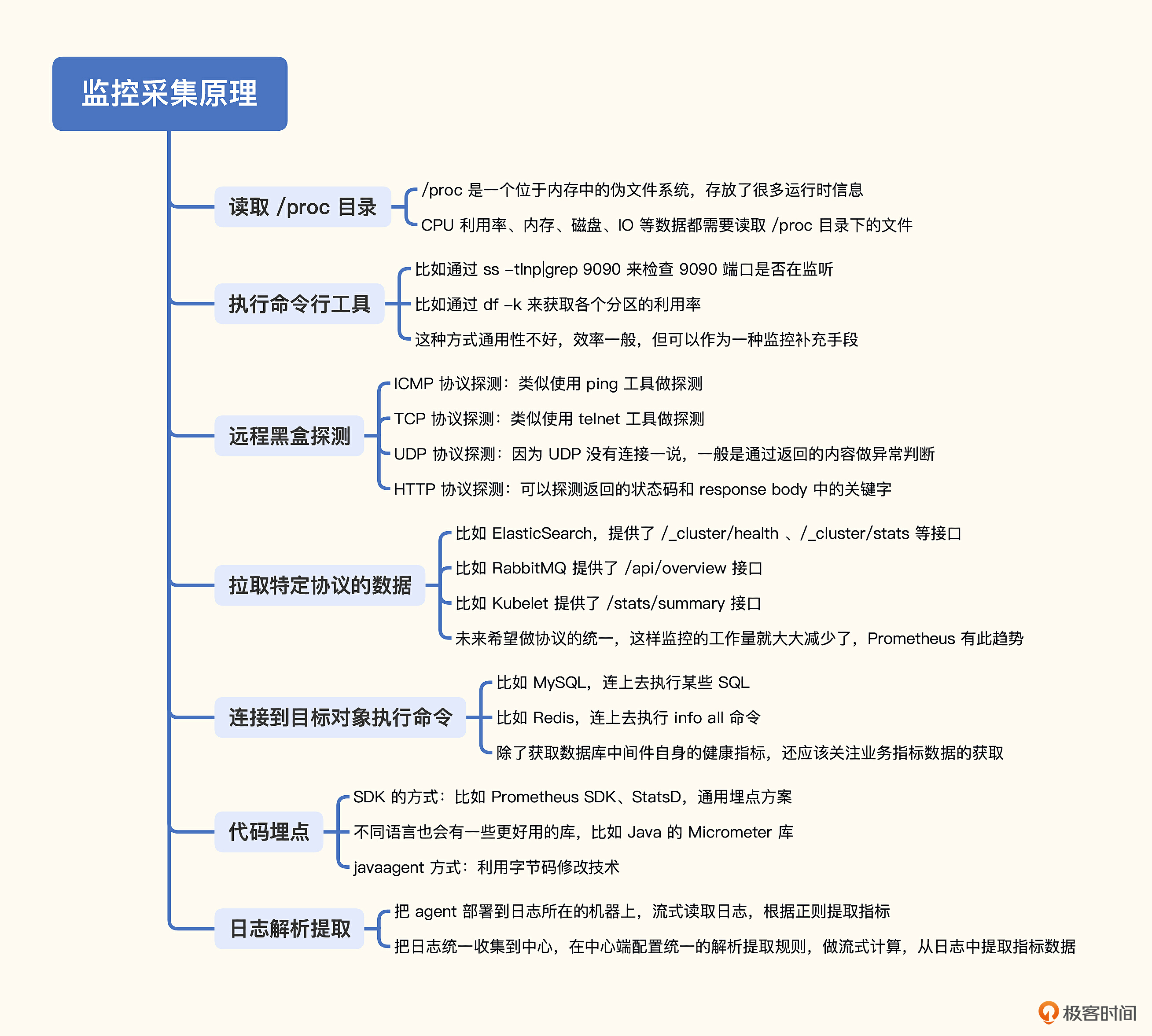
# 10. 监控采集方式及原理
# 11. 机器监控指标
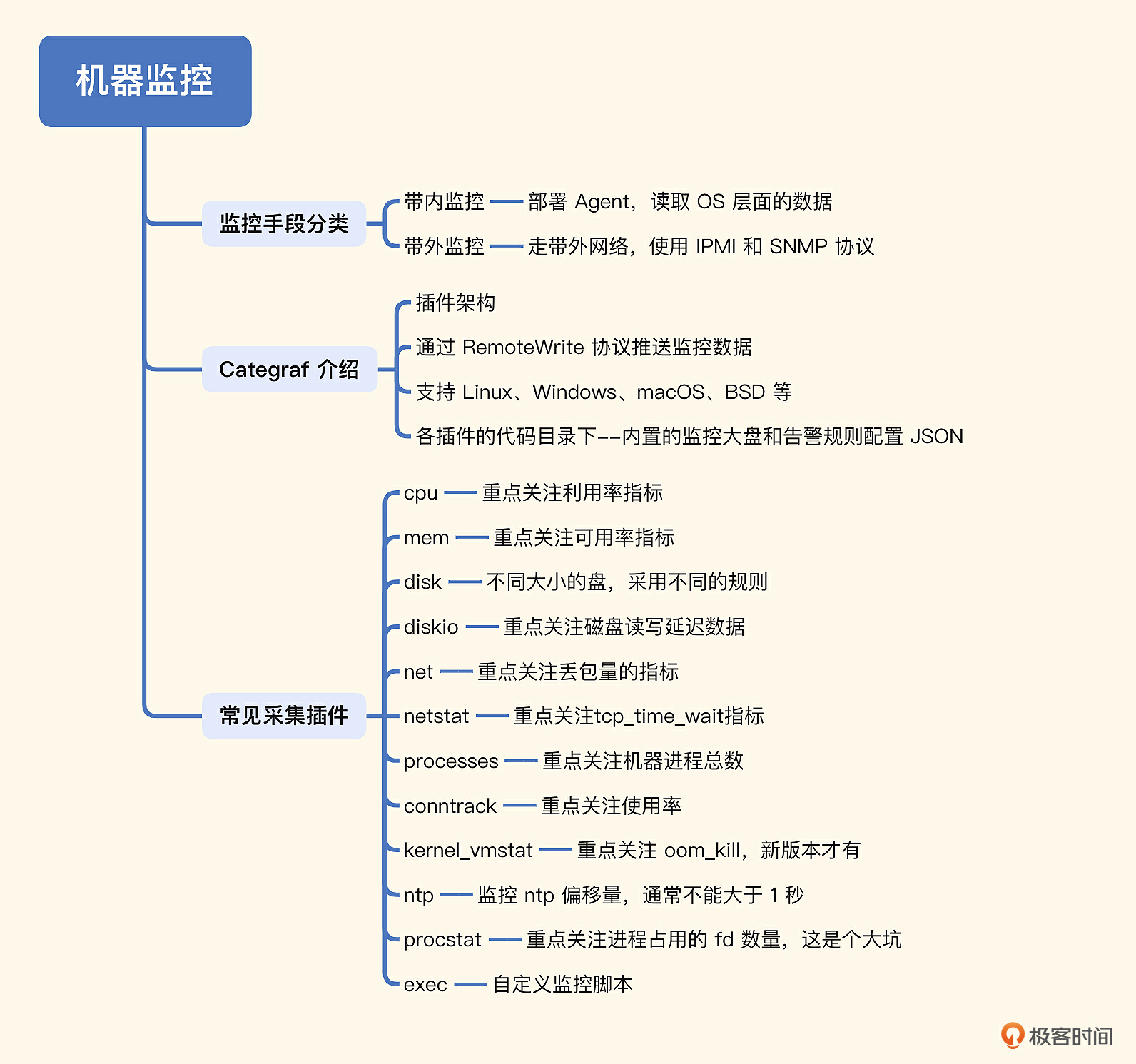
# 12. 网络监控指标

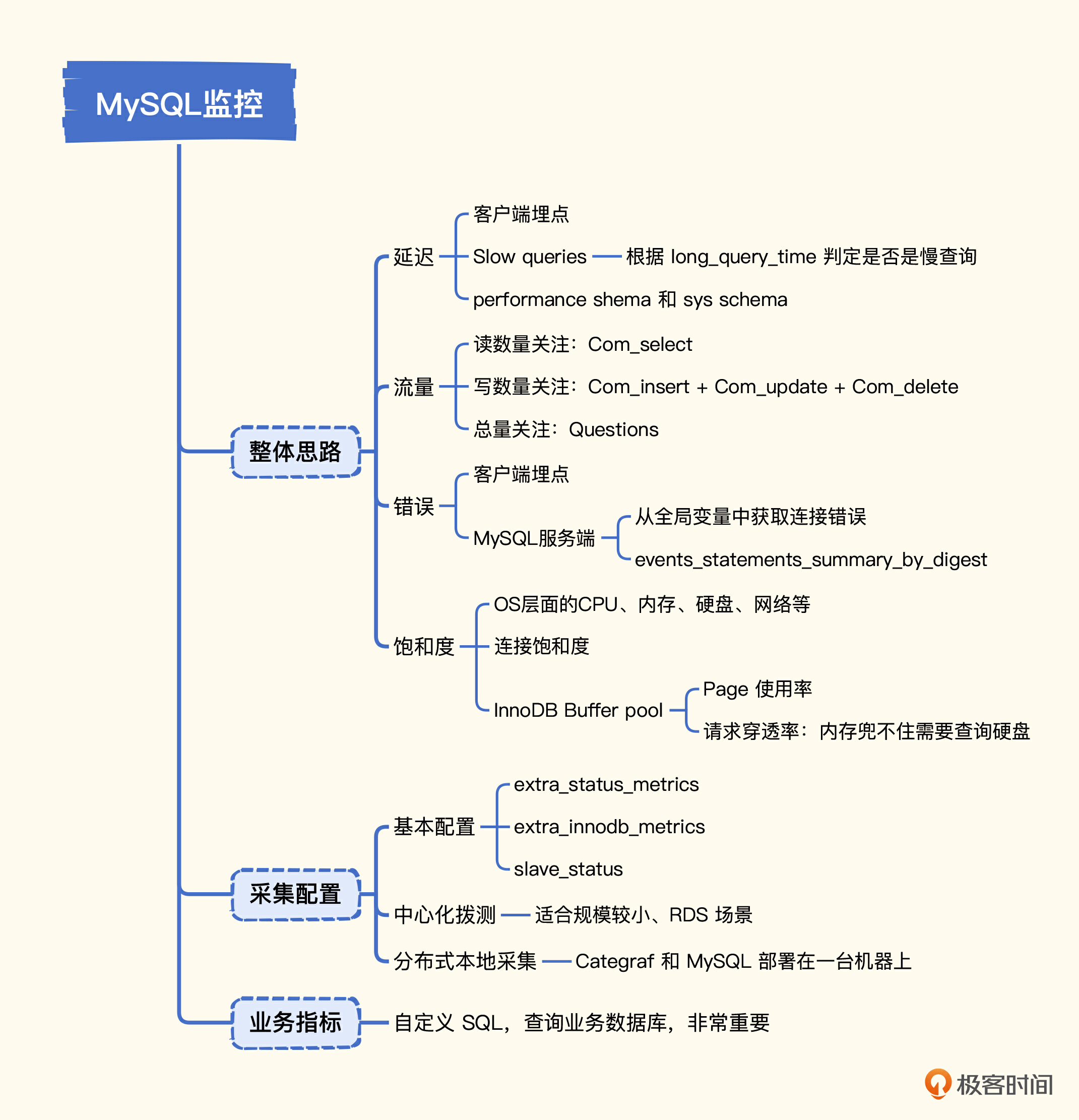
# 13. 组件监控-mysql
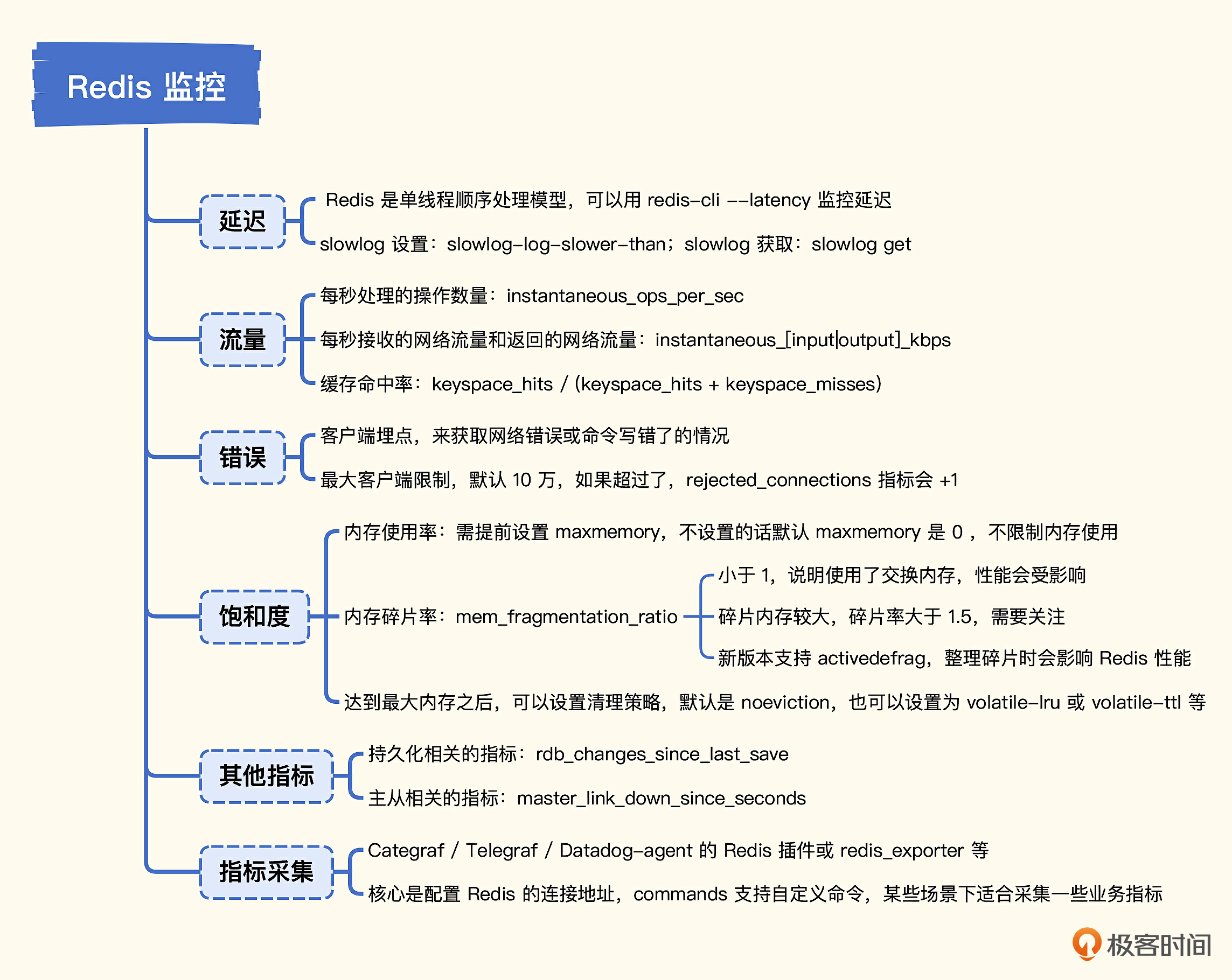
# 14. 组件监控-redis
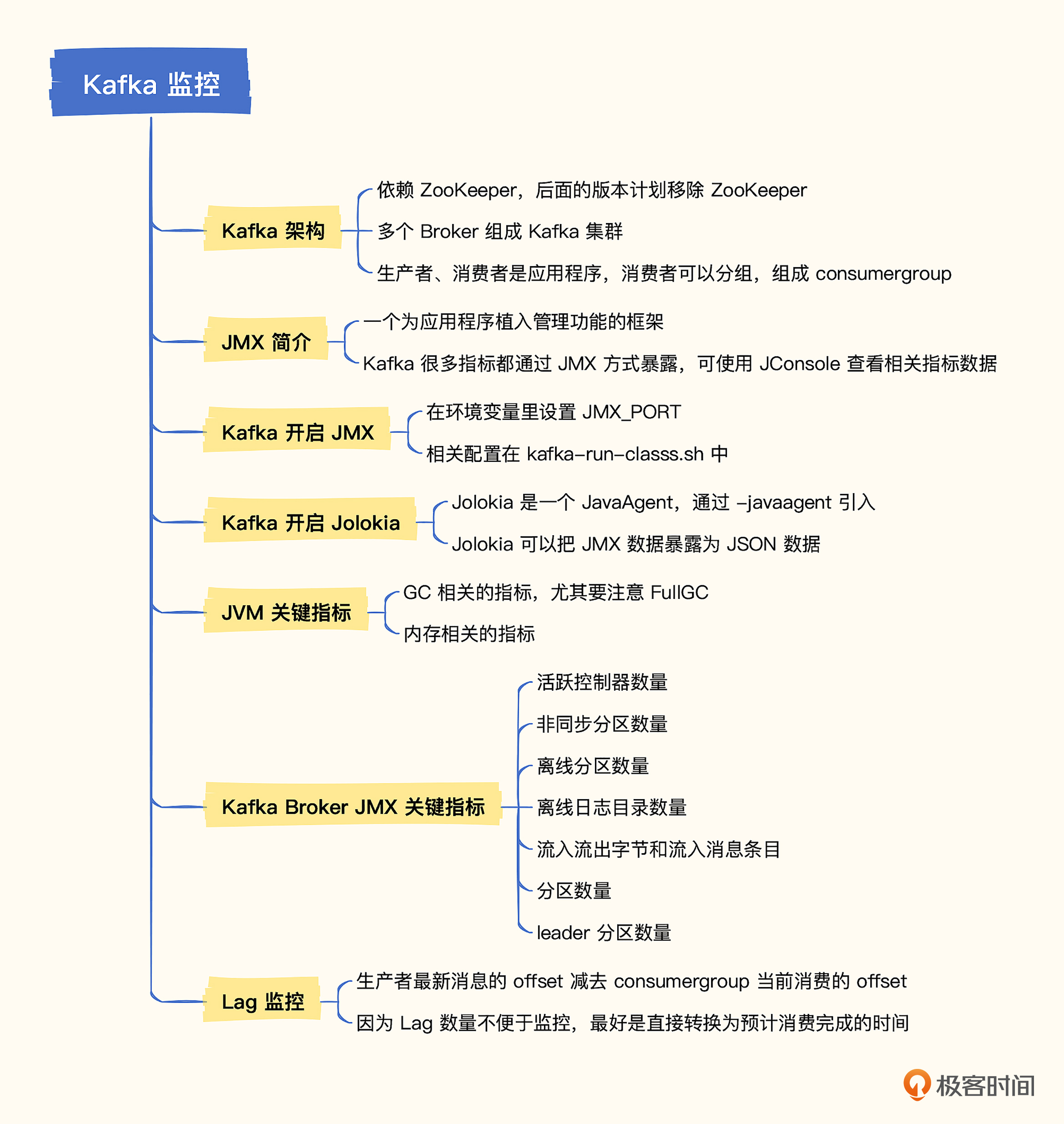
# 15. 组件监控-kafka
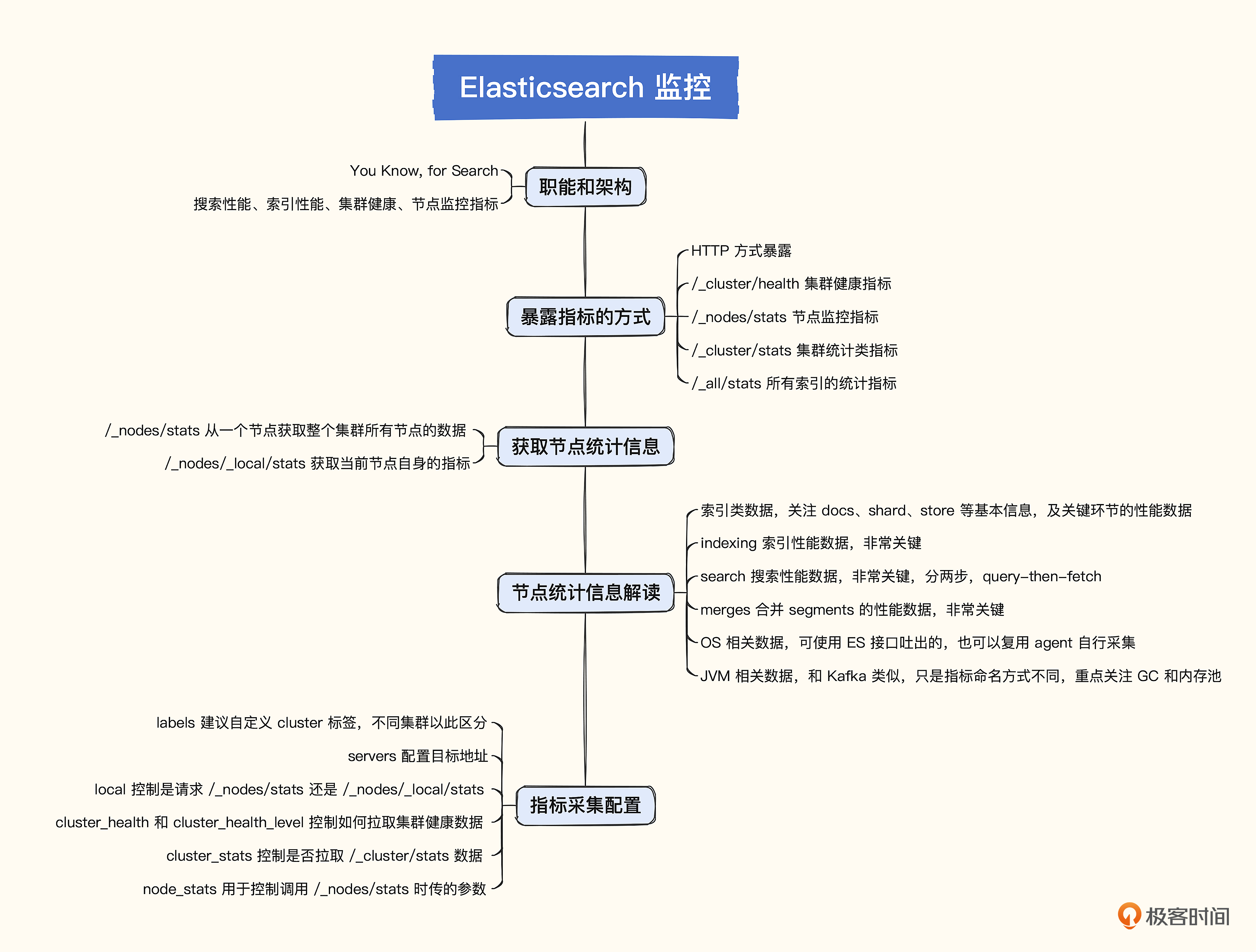
# 16. 组件监控-Elasticsearch
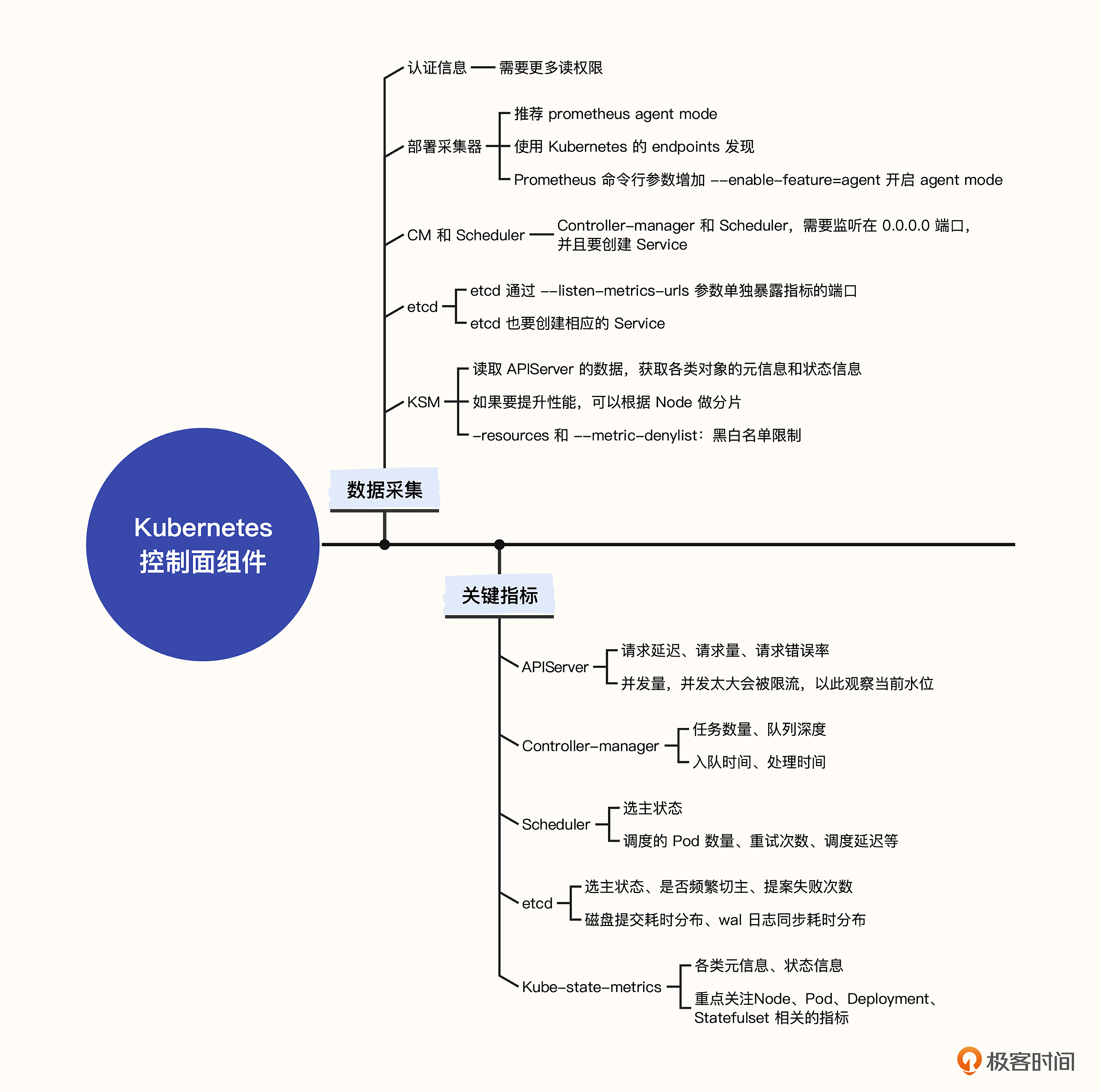
# 17. 组件监控-kubernets

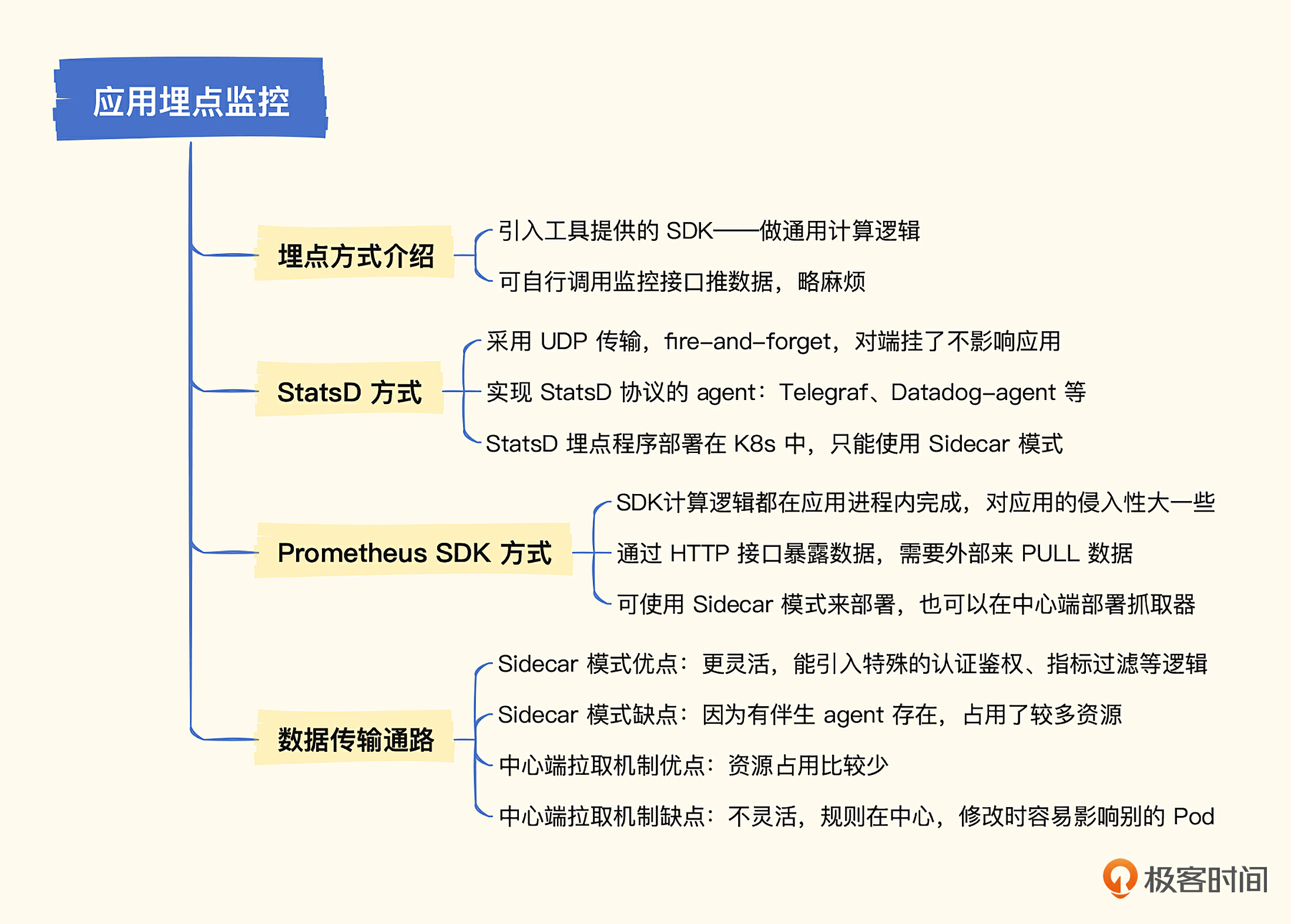
# 18. 应用监控-埋点监控
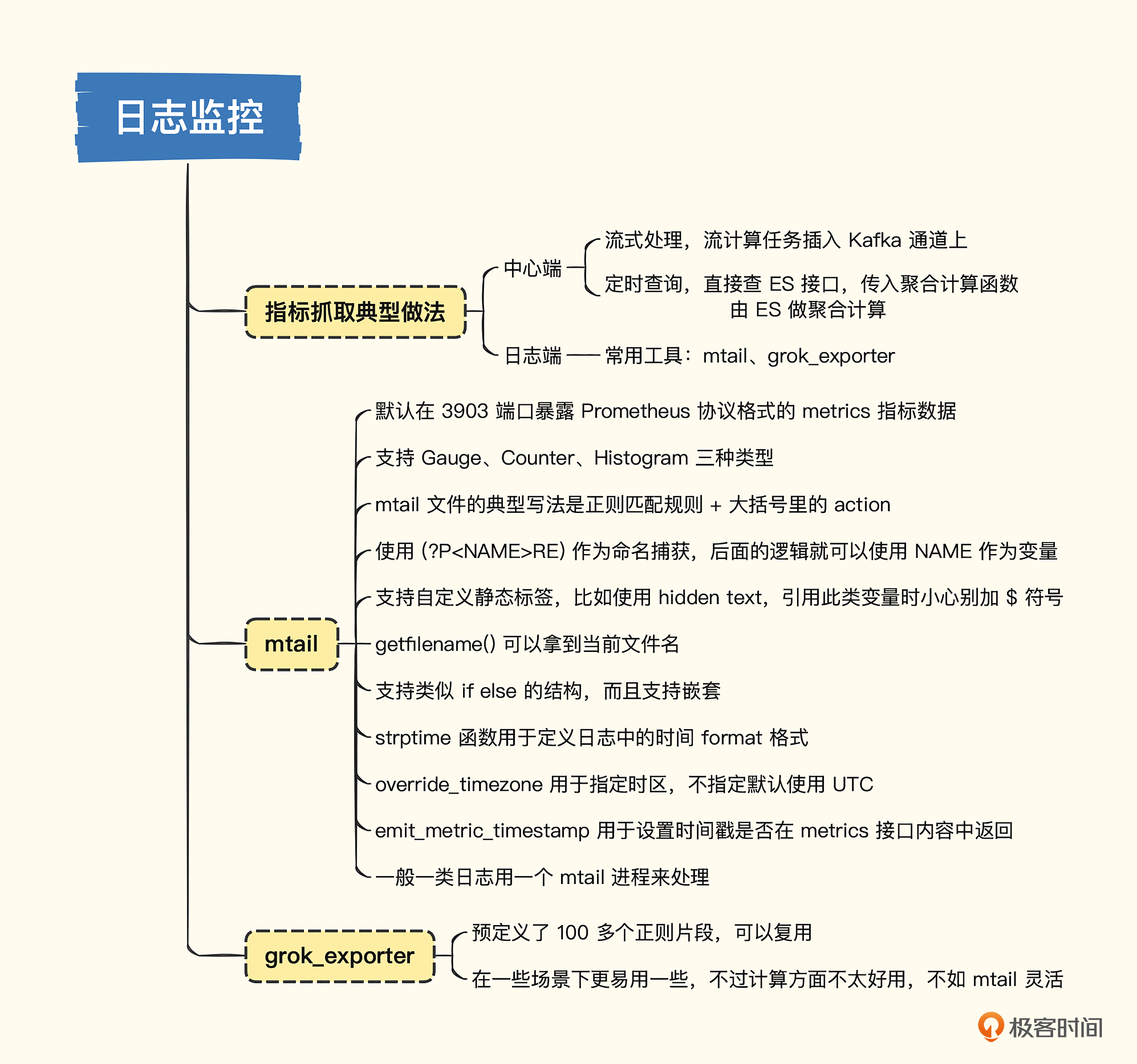
# 19. 应用监控-日志监控
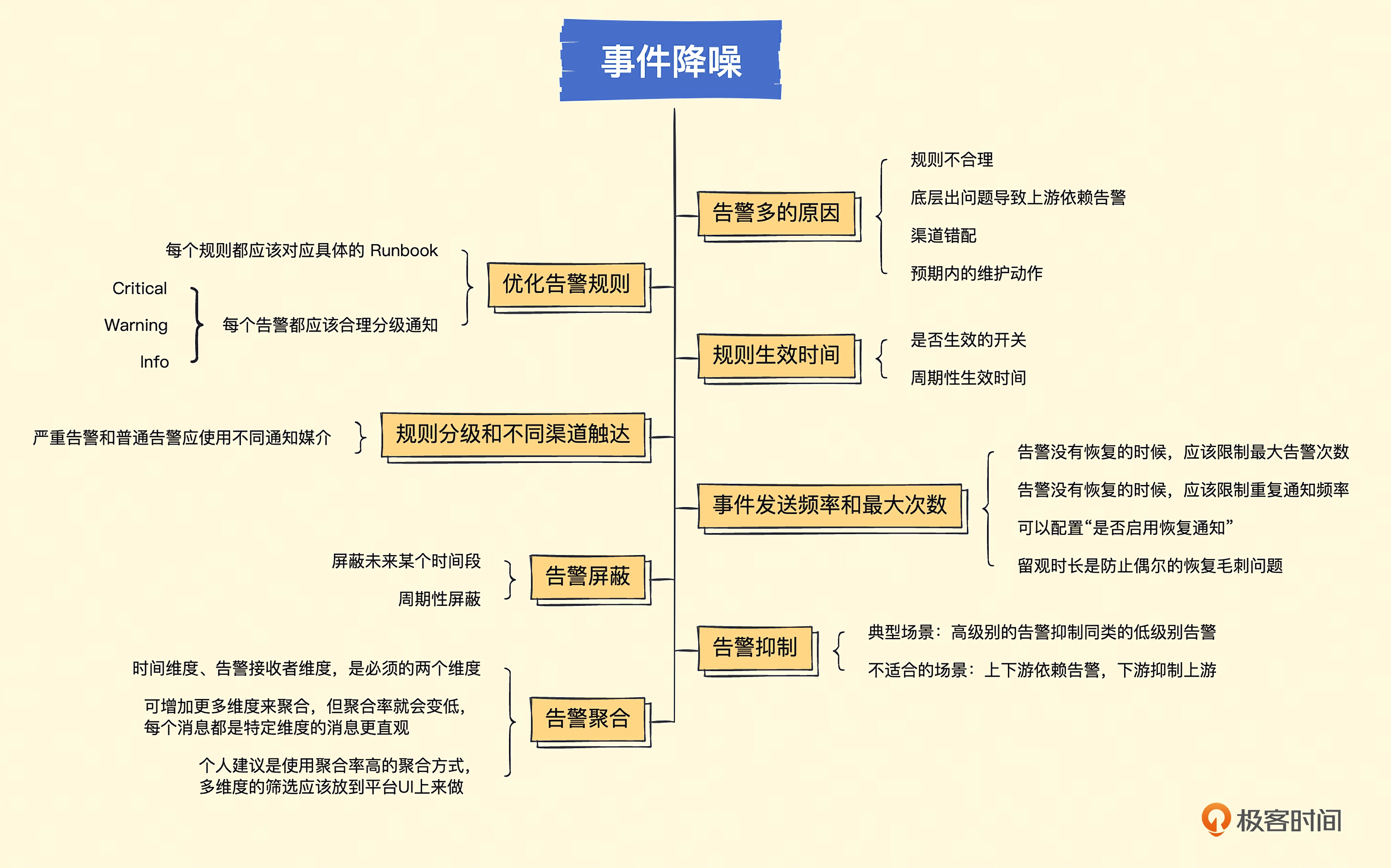
# 20. 告警事件管理-事件降噪
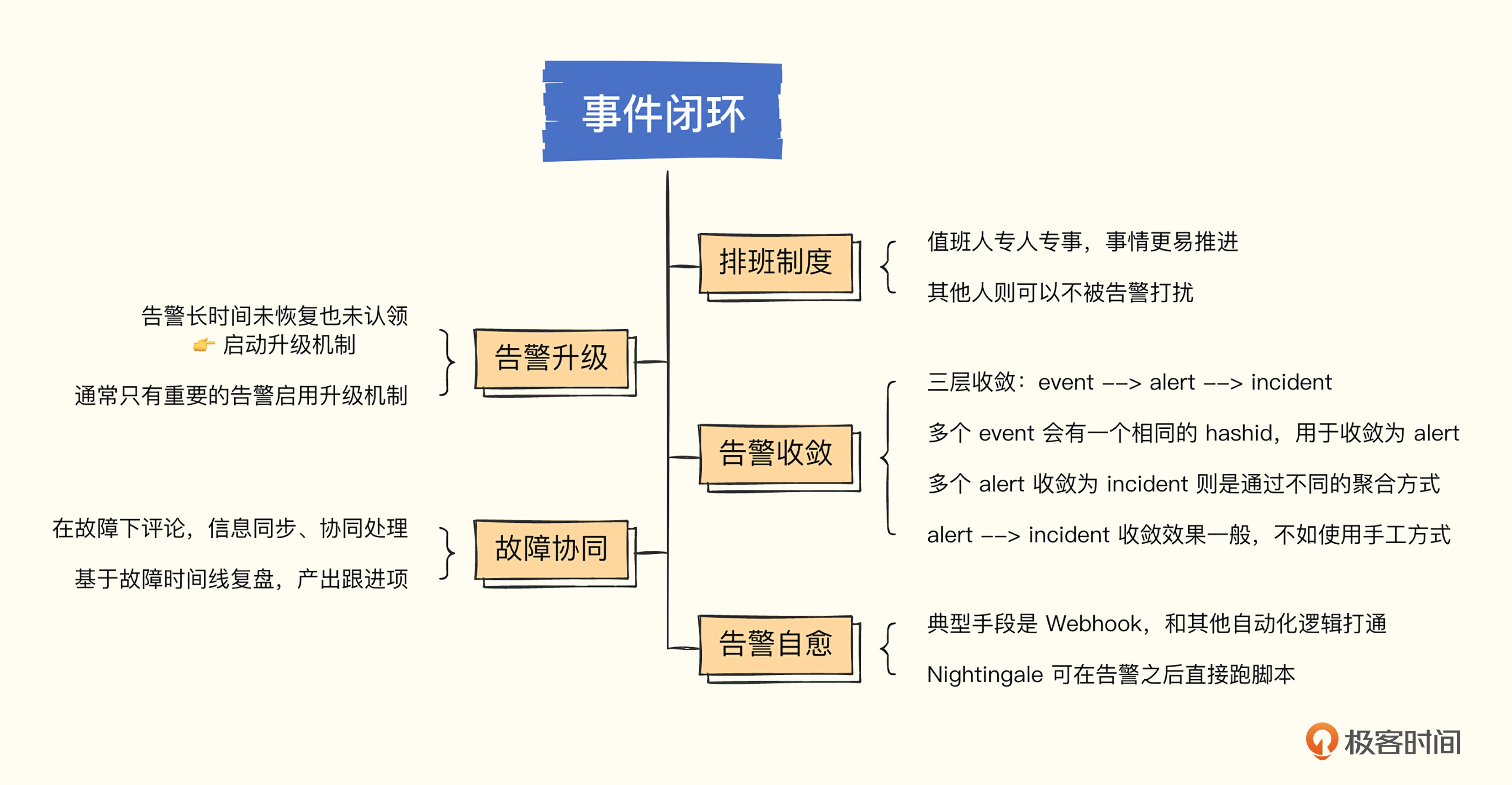
# 21. 告警事件管理-事件闭环
上次更新: 2023/03/14, 13:38:39