 k8s内存使用及监控
k8s内存使用及监控
# 1. node内存影响pod创建的因素
在node上执行命令free -m

参数说明:
Mem:表示物理内存统计
Swap:表示硬盘上交换分区的使用情况(k8s环境中一般会关闭swap)
total: 表示物理内存总量。
used: 表示已使用的内存
free: 未被分配的内存
shared: 共享内存,一般系统不会用到
buff/cache: 缓存内存数
total = used + free + buff/cache
pod在创建时node的内存数值会发生哪些改变?
# 1.1 node内存free值会不会影响pod创建
查看node的内存情况,剩余空闲内存为6502m

创建pod示例,内存requests设置为7000m
cat sample-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod-1
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
requests:
memory: "7000Mi"
cpu: "10m"
limits:
memory: "7000Mi"
cpu: "100m"
nodeSelector:
label-test: label-test
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
创建nginx-pod-1
kubectl apply -f sample-1.yaml
查看pod创建情况

查看此时node内存情况

也可能是由于nginx本身占用内存比较小,没有超过free值

进入pod内使用dd命令增大内存占用

查看此时pod内存情况,为6.6g。注意:此内存的增加主要是cache内存的增加

查看此时node内存情况

结论:pod创建时的资源调度不会受node内存free值的影响,pod的内存增加会优先占用node的free内存,pod的cache内存会计算到node的cache内存中
# 1.2 node能否回收pod的cache内存
此时node的free值为235m,再创建一个request内存为4096m的pod示例
cat sample-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod-2
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
requests:
memory: "4096Mi"
cpu: "10m"
limits:
memory: "4096Mi"
cpu: "100m"
nodeSelector:
label-test: label-test
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
执行创建
kubectl apply -f sample-2.yaml
查看pod创建情况

查看此时node内存情况,基本无变化

同理,可能新创建的nginx本身占用内存太小
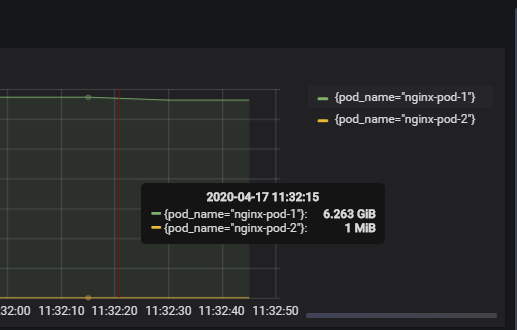
进入pod内使用dd命令增大内存占用

查看node的内存情况,基本无变化

查看此时pod内存情况,nginx-pod-1的内存占用变小,nginx-pod-2的内存占用变大
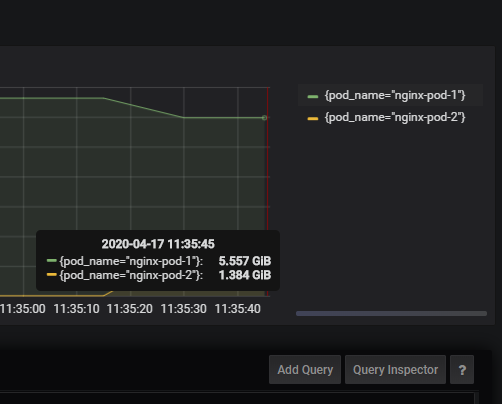
由此可见,nginx-pod-1的cache会被node回收,分配给nginx-pod-2
结论:node可以回收pod的cache内存
# 1.3 影响pod创建的因素
由linux内存机制可知,linux系统的实际可用内存为free+buff/cache,下面创建一个超过free+buff/cache值的pod,看能否创建成功
首先查看free 、buff/cache的值

该node实际可用内存 = free+buff/cache = 20744
创建一个request内存为21000m的pod示例,看能否创建成功
cat sample-3.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod-3
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
requests:
memory: "21000Mi"
cpu: "10m"
limits:
memory: "21000Mi"
cpu: "100m"
nodeSelector:
label-test: label-test
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
执行创建
kubectl apply -f sample-3.yaml
查看创建结果,为pending状态

查看详细输出
kubectl describe po/nginx-pod-3

Events提示内存不足
结论:pod的资源调度分配与node中free+buff/cache的值有关
# 2. 监控指标含义
目前存在的问题:
在实际监控指标中,node的free -m指标、阿里云k8s控制台内存监控指标、promethues内存监控指标都不一致
# 2.1 linux系统free计算方式
Linux系统中free命令显示的信息实际是从/proc/meminfo文件中计算得来

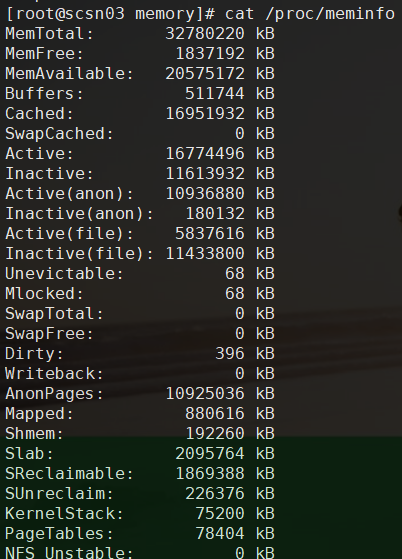
一般认为,buffer和cache是还可以再进行利用的内存,所以在计算空闲内存时,会将其剔除。
real_free = free_mem + buffer + cache
# 2.2 阿里云k8s控制台内存监控指标
K8s和docker的内存都是从cgroup的memory group来得到内存的原始文件,memory相关的主要文件如下:
ls /sys/fs/cgroup/memory/
cgroup.event_control #用于eventfd的接口
memory.usage_in_bytes #显示当前已用的内存
memory.limit_in_bytes #设置/显示当前限制的内存额度
memory.failcnt #显示内存使用量达到限制值的次数
memory.max_usage_in_bytes #历史内存最大使用量
memory.soft_limit_in_bytes #设置/显示当前限制的内存软额度
memory.stat #显示当前cgroup的内存使用情况
memory.use_hierarchy #设置/显示是否将子cgroup的内存使用情况统计到当前cgroup里面
memory.force_empty #触发系统立即尽可能的回收当前cgroup中可以回收的内存
memory.pressure_level #设置内存压力的通知事件,配合cgroup.event_control一起使用
memory.swappiness #设置和显示当前的swappiness
memory.move_charge_at_immigrate #设置当进程移动到其他cgroup中时,它所占用的内存是否也随着移动过去
memory.oom_control #设置/显示oom controls相关的配置
memory.numa_stat #显示numa相关的内存
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
在k8s中,统计node和pod内存使用量是通过 metric-server/heapster 获取cadvisor中working_set的值,来表示使用内存大小,working_set计算方式如下:
working_set= memory.usage_in_bytes - total_inactive_file
memory.usage_in_bytes = memory.kmem.usage_in_bytes + rss + cache
2
内存使用率也可表示为:
container_memory_working_set_bytes / memory.limit_in_bytes
# 2.2.1 node内存指标
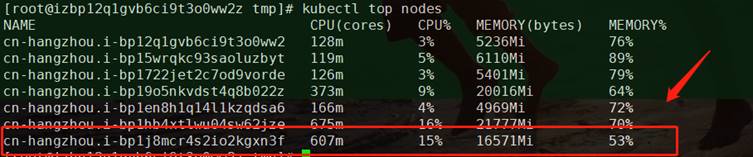
node中Cgroup中内存原始数据为:

working_set= memory.usage_in_bytes - total_inactive_file = (29070221312 – 11707129856)/1024/1024 = 16532
得出结果与阿里云控制台node指标相吻合:
# 2.2.2 pod内存指标
同上
注意:需要进入容器内的/sys/fs/cgroup/memory取值
提示:在kubelet中节点内存不足时以working_set判断pod是否OOM的标准
扩展:
Docker通过docker stat获取的,内存使用量的计算方式为:
memory.usage = memory.usage_in_bytes - cache1由于:
memory.usage_in_bytes = memory.kmem.usage_in_bytes + rss + cache1则:
memory.usage = memory.kmem.usage_in_bytes + rss1
# 2.3 prometheus中的监控指标
# 2.3.1 现有memory监控
K8s cluster memory
sum(node_memory_MemTotal_bytes{job="host-prod",instance=~"pcsn.\*"}) by (instance) - sum(node_memory_MemAvailable_bytes{job="host-prod",instance=~"pcsn.\*"}) by (instance) + sum(node_memory_Cached_bytes{job="host-prod",instance=~"pcsn.\*"}) by (instance) + sum(node_memory_Buffers_bytes{job="host-prod",instance=~"pcsn.\*"}) by (instance)
K8s container memory
sum(container_memory_usage_bytes{env="prod",namespace="prod",container_name=~"xxx-app|xxxx-app.\*|xxxx-app.\*"}) by (container_name)
# 2.3.2 memory监控指标建议
- K8s cluster memory:
sum(node_memory_MemTotal_bytes{job="host-prod",instance=~"pcsn.\*"}) by (instance) - sum(node_memory_MemFree_bytes{job="host-prod",instance=~"pcsn.\*"}) by (instance) - sum(node_memory_Inactive_file_bytes{job="host-prod",instance=~"pcsn.\*"}) by (instance)
说明:
在prometheus中node的 working_set 指标不存在,由于
working_set = memory.usage_in_bytes - total_inactive_file
memory.usage_in_bytes ≈ node_memory_MemTotal_bytes - node_memory_MemFree_bytes
2
所以
working_set = node_memory_MemTotal_bytes - node_memory_MemFree_bytes - total_inactive_file
- K8s container memory:
sum(container_memory_working_set_bytes{env="prod",namespace="prod",container_name=~"hardcoreex-app|bluewhale-app.\*|importer-app.\*"}) by (container_name)
说明:container_memory_usage_bytes 和 container_memory_working_set_bytes 值大致相同,由于pod OOM的标准以container_memory_working_set_bytes,所以监控指标最好以container_memory_working_set_bytes为准。