 什么是并发
什么是并发
# 1. 什么是并发
很久以前,面向大众消费者的主流处理器(CPU)都是单核的,操作系统的基本调度与执行单元是进程(process)。这个时候,用户层的应用有两种设计方式:
一种是单进程应用,也就是每次启动一个应用,操作系统都只启动一个进程来运行这个应用。
单进程应用的情况下,用户层应用、操作系统进程以及处理器之间的关系是这样的:

这个设计下,每个单进程应用对应一个操作系统进程,操作系统内的多个进程按时间片大小,被轮流调度到仅有的一颗单核处理器上执行。换句话说,这颗单核处理器在某个时刻只能执行一个进程对应的程序代码,两个进程不存在并行执行的可能。
并行(parallelism),指的就是在同一时刻,有两个或两个以上的任务(这里指进程)的代码在处理器上执行。
总的来说,单进程应用的设计比较简单,它的内部仅有一条代码执行流,代码从头执行到尾,不存在竞态,无需考虑同步问题。
另外一种是多进程应用,也就是应用通过 fork 等系统调用创建多个子进程,共同实现应用的功能。
多进程应用的情况下,用户层应用、操作系统进程以及处理器之间的关系是这样的:
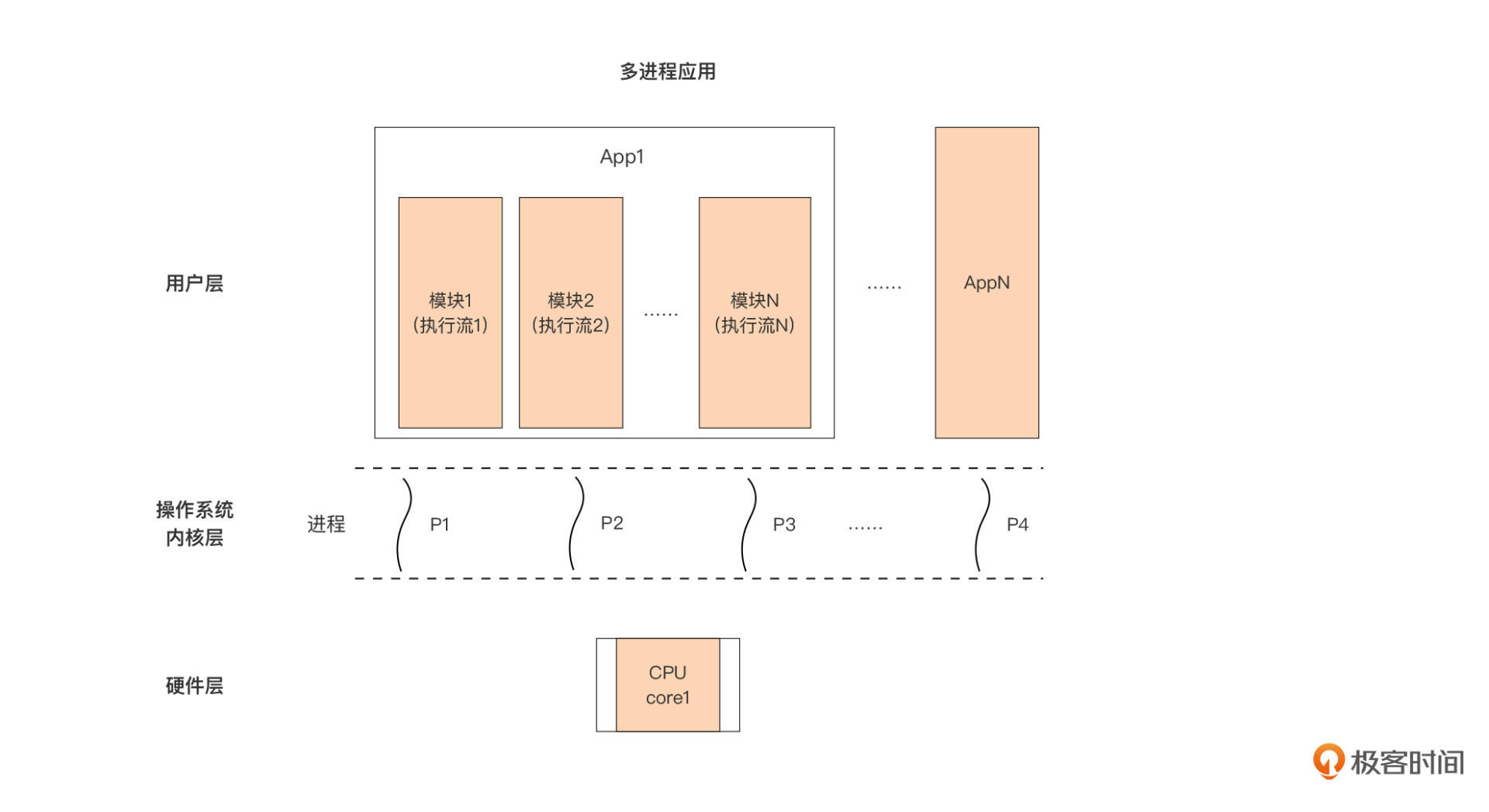
以图中的 App1 为例,这个应用设计者将应用内部划分为多个模块,每个模块用一个进程承载执行,每个模块都是一个单独的执行流,这样,App1 内部就有了多个独立的代码执行流。但限于当前仅有一颗单核处理器,这些进程(执行流)依旧无法并行执行,无论是 App1 内部的某个模块对应的进程,还是其他 App 对应的进程,都得逐个按时间片被操作系统调度到处理器上执行。
多进程应用由于将功能职责做了划分,并指定专门的模块来负责,所以从结构上来看,要比单进程更为清晰简洁,可读性与可维护性也更好。
**这种将程序分成多个可独立执行的部分的结构化程序的设计方法,就是并发设计。**采用了并发设计的应用也可以看成是一组独立执行的模块的组合。
进程并不适合用于承载采用了并发设计的应用的模块执行流。因为进程是操作系统中资源拥有的基本单位,它不仅包含应用的代码和数据,还有系统级的资源,比如文件描述符、内存地址空间等等。进程的“包袱”太重,这导致它的创建、切换与撤销的代价都很大。
于是线程便走入了人们的视野,线程就是运行于进程上下文中的更轻量级的执行流。同时随着处理器技术的发展,多核处理器硬件成为了主流,这让真正的并行成为了可能,于是主流的应用设计模型变成了这样:

基于线程的应用通常采用单进程多线程的模型,一个应用对应一个进程,应用通过并发设计将自己划分为多个模块,每个模块由一个线程独立承载执行。多个线程共享这个进程所拥有的资源,但线程作为执行单元可被独立调度到处理器上运行。
线程的创建、切换与撤销的代价相对于进程是要小得多。当这个应用的多个线程同时被调度到不同的处理器核上执行时,就说这个应用是并行的。
并发与并行概念区分:
Go 语言之父 Rob Pike 曾说过:并发不是并行,并发关乎结构,并行关乎执行。
并发是在应用设计与实现阶段要考虑的问题。并发考虑的是如何将应用划分为多个互相配合的、可独立执行的模块的问题。
采用并发设计的程序并不一定是并行执行的,在不满足并行必要条件的情况下(也就是仅有一个单核 CPU 的情况下),即便是采用并发设计的程序,依旧不可以并行执行。而在满足并行必要条件的情况下,采用并发设计的程序是可以并行执行的。而那些没有采用并发设计的应用程序,除非是启动多个程序实例,否则是无法并行执行的。
传统编程语言(如 C、C++ 等)基于多线程模型支持并发的方式有很多不足:
复杂
线程创建容易退出难(线程退出要考虑新创建的线程是否要与主线程分离(detach),还是需要主线程等待子线程终止(join)并获取其终止状态?又或者是否需要在新线程中设置取消点(cancel point)来保证被主线程取消(cancel)的时候能顺利退出。);
并发执行单元间的通信困难且易错(多个线程之间的通信虽然有多种机制可选,但用起来也是相当复杂。并且一旦涉及共享内存,就会用到各种锁互斥机制,死锁便成为家常便饭。另外,线程栈大小也需要设定,开发人员需要选择使用默认的,还是自定义设置。)。
难于规模化(scale)
线程的使用代价虽然已经比进程小了很多,但依然不能大量创建线程,因为除了每个线程占用的资源不小之外,操作系统调度切换线程的代价也不小。
对于很多网络服务程序来说,由于不能大量创建线程,只能选择在少量线程里做网络多路复用的方案,也就是使用 epoll/kqueue/IoCompletionPort 这套机制,即便有像libevent和libev这样的第三方库帮忙,写起这样的程序也是很不容易的,存在大量钩子回调,给开发人员带来不小的心智负担。